Still Image and Video Compression with MATLAB
Teks penuh
Gambar


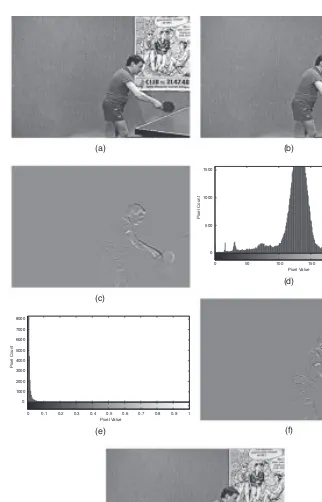



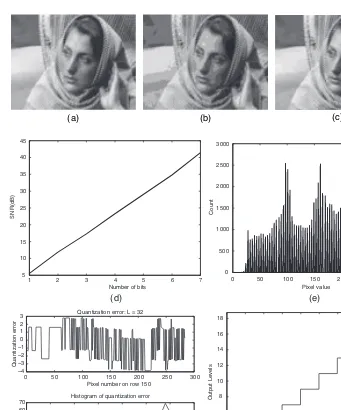

Garis besar
Dokumen terkait
[r]
Kesesuaian rencana kerja dengan jenis pengeluaran biaya, volume kegiatan dan jenis pengeluaran,. dan biaya satuan dibandingkan dengan biaya lang berlaku di
“Bagaimana perasaan bapak saat ini, adakah hal yang menyebabkan bapak marah?” “Baik, sekarang kita akan belajar cara mengontrol perasaan marah dengan kegiatan fisik untuk cara
kondisi normal, yaitu sebuah kondisi dimana tidak akan terjadi perubahan nilai secara signifikan dari intensitas cahaya pada posisi. webcam dan kondisi
bola menggunakan punggung kaki dalam permainan Juggling. d) Menyiapkan alat yang akan digunakan pada pembelajaran. 2) Tahap Pelaksanaan Tindakan.. Pada pelaksanaan tindakan
2) Tahapan-tahapan apa saja yang anda lakukan berkaitan dengan upaya membatasi paparan pasien terhadap infeksi yang berasal dari pengunjung? 3) Apa hambatan
IMPLEMENTASI NILAI-NILAI DEMOKRASI DALAM ORGANISASI KESISWAAN (Studi Deskriptif di SMA Negeri 1 Lembang).. DISETUJUI DAN DISAHKAN OLEH
4.2.2 Gambaran Perilaku Kewirausahaan Pengusaha Mochi Berdasarkan Jenis Kelamin, Usia, Latar Belakang Pendidikan Formal dan.. Pengalaman
