C++ Unleashed Ebook free download pdf pdf
Teks penuh
Gambar
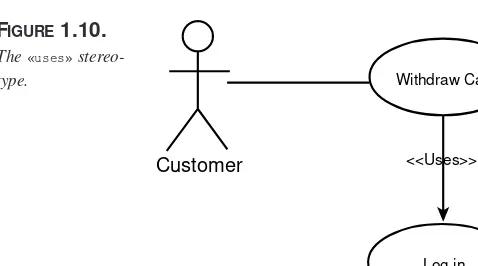
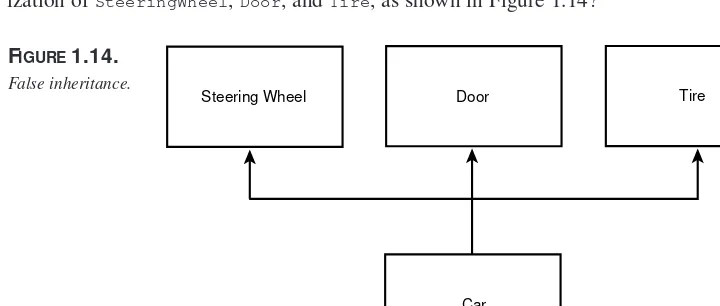


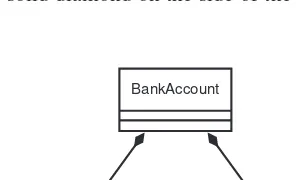
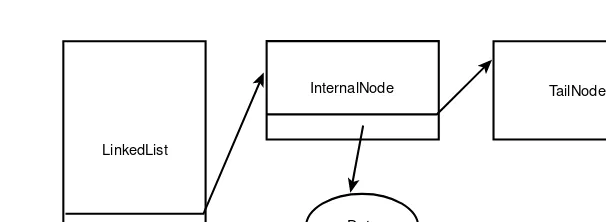



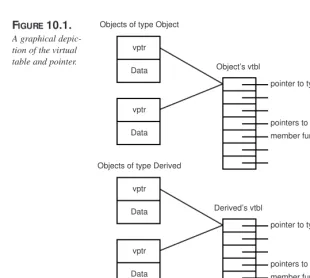
Garis besar
Dokumen terkait
Sebagai salah satu kota pendidikan di Jawa Timur, Malang memiliki banyak tempat, budaya, dan keragaman tanaman yang menarik untuk dicoba dan dijelajahi.. Salah satu sudut Kota
Skripsi ini merupakan salah satu persyaratan bagi mahasiswa Program Studi Teknik Lingkungan, Fakultas Teknik Sipil dan Perencanaan, UPN “Veteran” Jawa Timur untuk mendapatkan
Jadi nilai religius notabene sangat tepat jika menggunakan metode pembiasaan karena dengan pembiasaan tersebut dapat mempermudah kita dalam mengajarkan kepada
Skripsi Studi Penggunaan Obat Kemoterapi Pada Pasien Kanker Paru … Nevi Rahmi Alfiasari... ADLN Perpustakaan
The purpose of this research is to improve writing skill for the eighth grade students of SMP 4 Kudus in academic year 2013/2014.. The writer conducted a classroom action
Tujuan penelitian ini untuk meningkatkan penyesuaian diri melalui layanan bimbingan kelompok siswa kelas X Administrasi Perkantoran 1 SMKN 1 Kudus tahun pelajaran
Penelitian ini bertujuan untuk mengetahui sikap pengunjung Dolly terhadap penayangan iklan kondom di televisi serta situasi dan kondisi apa saja yang menentukan sikap pengunjung
Populasi terendah terjadi pada perlakuan B konsentrasi (30 ppm pupuk urea + 10 ppm perasan Eucheuma sp.) dengan populasi N. Hal ini menunjukkan bahwa
