Networking A Beginner's Guide pdf pdf
Teks penuh
Gambar
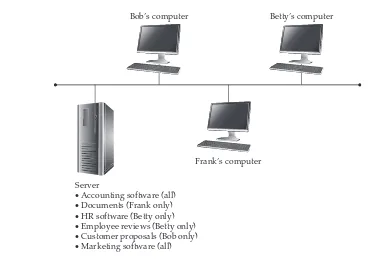
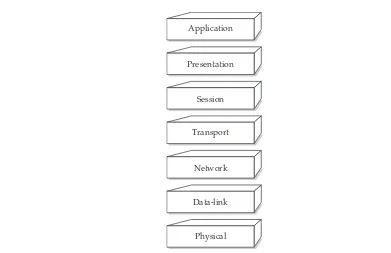
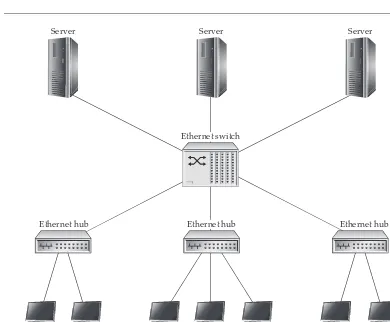
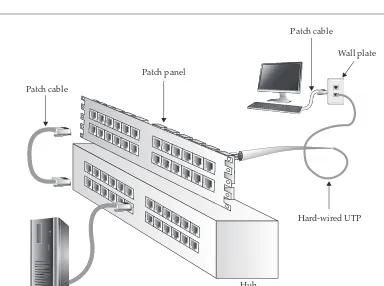

Garis besar
Dokumen terkait
Implikasi potensial dari risiko adalah bahwa penjualan akan jatuh di bawah tingkat penjualan yang direncanakan, karena dipengaruhi oleh proporsi relatif
Said Sukanto Tahun 2017.--- ---Acara pembukaan dokumen penawaran dilaksanakan sesuai jadwal dimulai pukul 09.01 WIB s/d 23.59 WIB melalui aplikasi LPSE, dangan hasil
Peserta yang memasukkan penawaran dapat menyampaikan sanggahan secara elektronik melalui aplikasi SPSE atas penetapan pemenang kepada Pokja dengan disertai bukti
Dengan ini disampaikan bahwa berdasarkan Surat Penetapan Pemenang Nomor : 142/08/POKJA-BLPBJ.MKS/VII/2017 Tanggal 05 Juli 2017, Kami Pokja BLP Bagian Layanan
Sesuai dengan ketentuan dalam Peraturan Presiden Republik Indonesia Nomor 4 Tahun 2015 Tentang Perubahan Keempat Atas Peraturan Presiden Nomor 54 Tahun 2010 Tentang
Pemutusan Oleh Penyedia 44.1 Menyimpang dari Pasal 1266 dan 1267 Kitab Undang-Undang Hukum Perdata, Penyedia dapat memutuskan Kontrak ini melalui pemberitahuan tertulis kepada
Karena penyakit ini tergolong penyakit ringan pada anak-anak, bahaya medis yang utama dari penyakit ini adalah infeksi pada wanita hamil yang dapat
Untuk menja min hak-hak dan kewa jiban setiap penduduk Madinah, Rasulullah me mp raka rsai penyusunan piagam perjanjian yang disebut Piagam Madinah. Dengan piagam ini
