The design and implementation of the 4 4 BSD operating system pdf pdf
Teks penuh
Gambar

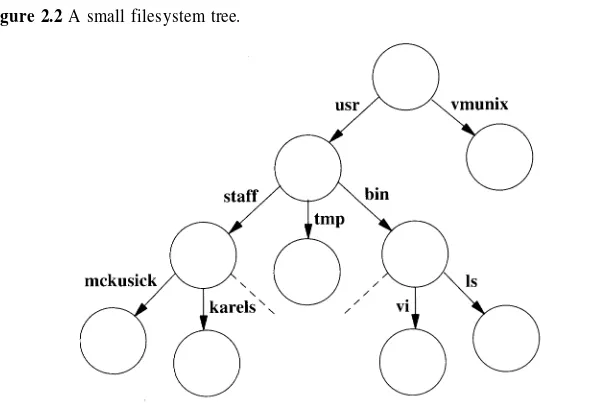
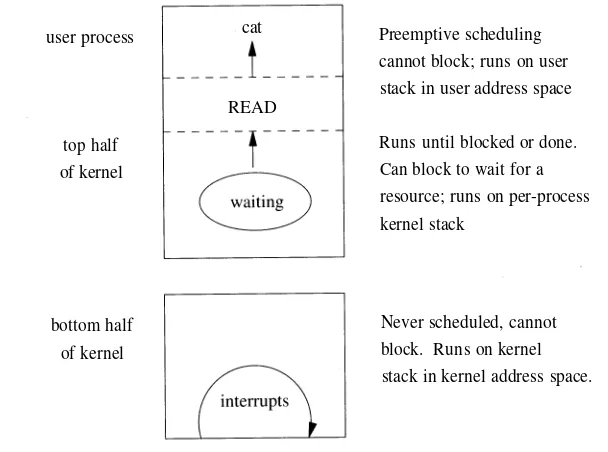
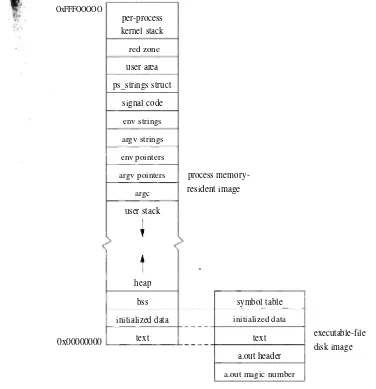
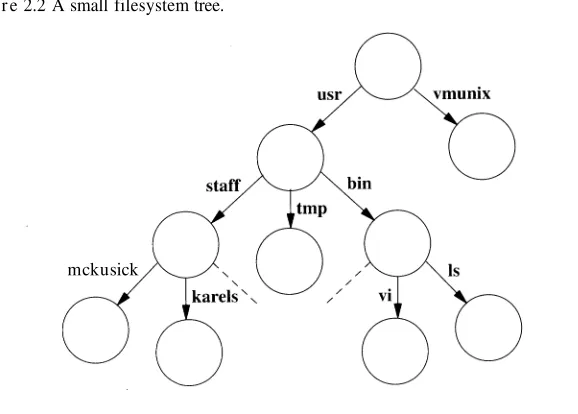


Dokumen terkait
The disadvantages are the PV panel can only provide charging current when its output voltage is higher than the battery voltage and the system does not always work at the
power and moderate difficulty level. The items that considered as not valid, reliable, poor discrimination power and the difficulty level are too easy or too difficult are the
Therefore, the design of accounting information systems using Microsoft Access applications that are designed following the needs and business characteristics of MSMEs
Because of the difficulty in determining the fair value of fixed assets that are not actively traded in the market, it causes additional costs to be incurred by the company
Cash Expenditure Transaction Cash expenditure transactions at PT Karya Mura Niaga are usually made on the payment of debts from inventory purchases, payment of operating expenses, and
Analysis In the analysis stage, the activities carried out are, analyzing the videolife story and wisdom of the eldery content that will be made, starting from determining 3 sources
EXPERIMENTAL RESULT AND DISCUSSION The prototype is designed to control and detect the electric faults which are both emergency under voltage, overvoltage and short circuit current and
This research was carried out using the AHP method to calculate the value of each criterion using price, screen size, processor type, memory capacity, hard disk capacity, and
