Java Network Programming Developing Networked Applications 4th Edition pdf pdf
Teks penuh
Gambar



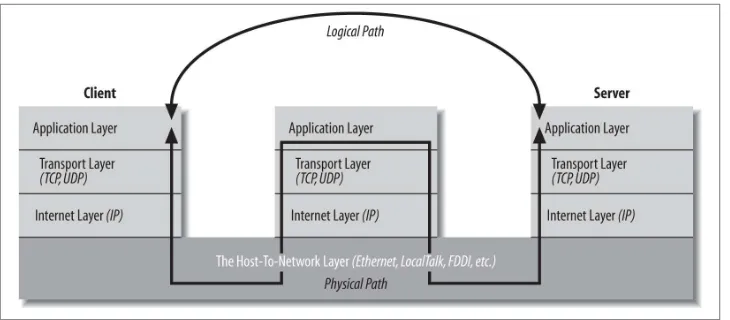
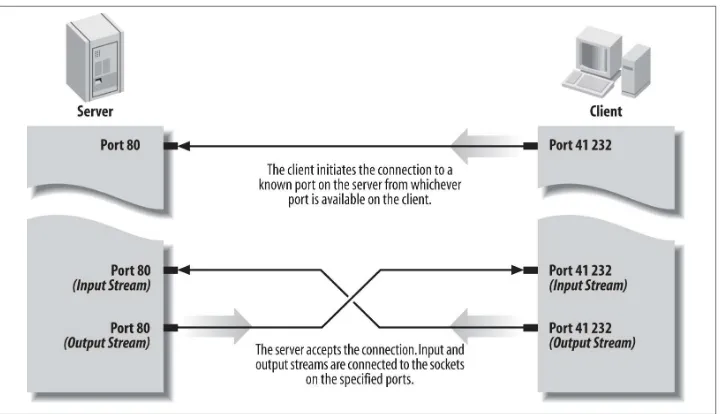
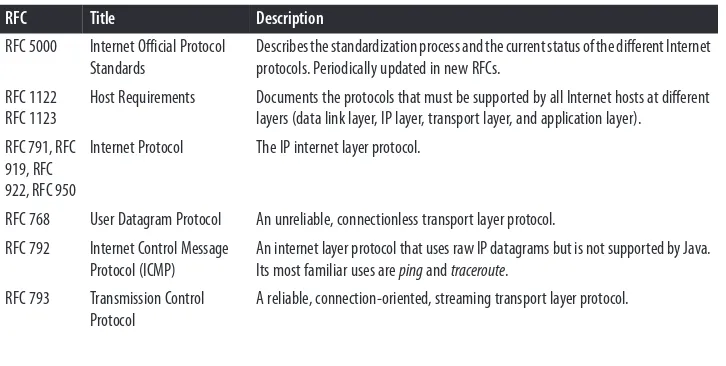
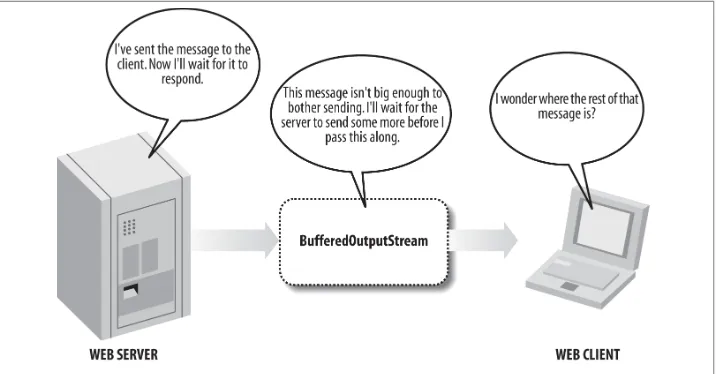
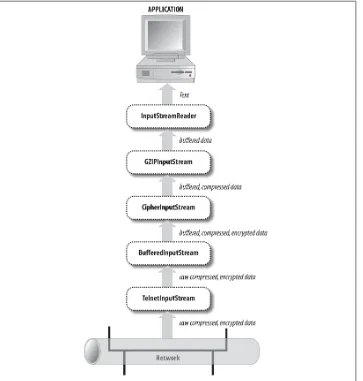
Dokumen terkait
9 Anda memutuskan untuk membeli dan mengkonsumsi produk Chicken Holic karena sesuai dengan yang Anda harapkan/butuhkan 10 Anda merasa akan melakukan pembelian. kembali produk
Pengolahan data dilakukan dengan bantuan software AutoCAD 2008 dan minecom 4.118. Data yang di input yaitu adalah data koordinat dan elevasi ketinggian untuk pembuatan
Alasan utamanya, dan untuk kepopuleran pendanaan pada proyek, adalah para donatur butuh untuk menyebarkan resiko finansialnya (financial risks), dan tidak seperti pendanaan inti
[r]
Secara umum kuisioner ini digunakan untuk memperoleh data kuantitatif tentang implementasi mekanisme good corporate governance di UKM dengan memberikan persepsi
Pada hari ini Senin tanggal Delapan Belas Bulan Juni Tahun Dua Ribu Dua Belas, bertempat di Aula Dinas Kesehatan Kota Tangerang Selatan, kami Panitia Pengadaan
Mata kuliah ini mengarahkan mahasiswa agar dapat menerapkan metode pengembangan bahasa di Taman Kanak-Kanak melalui pengkajian hakekat perkembangan bahasa anak; teori dasar
The journal publishes research papers in the fields of Social Sciences, Education, Philosophy, Linguistics, Literature, Psychology.. However research in all social science
