big data now 2015 edition pdf pdf
Teks penuh
Gambar

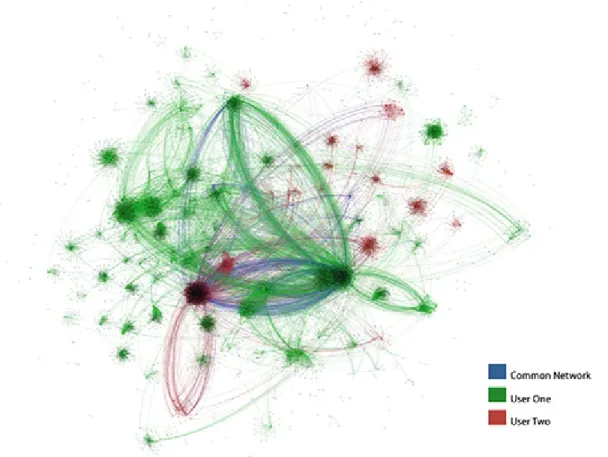
Garis besar
Dokumen terkait
Laboratorium merupakan suatu kesatuan yang secara legal dapat dipertanggungjawabkan. Kegiatan laboratorium dilakukan dengan sebaik-baiknya sehingga dapat memberikan data
Laser Jaya Sakti Pasuruan”.Tujuannya untuk mengetahui pengaruh variabel pendidikan dan pelatihan tenaga kerja secara simultan dan parsial terhadap kinerja karyawan
“ Studi Tentang Pener apan Pencatatan Keuangan Bagi Pelaku Usaha Kecil dan Menengah (UKM) ; (Studi Kasus Pada Tiga Counter Pulsa di Kecamatan Kenjer an) ”..
Tabel 4.3 Distribusi Hasil Belajar Matematika Berdasarkan Skor Maksimum, Skor Minimum, dan Skor Rata-rata Siswa Pra Siklus
Penelitian pembuatan bioetanol dari limbah biji rambutan bertujuan untuk meneliti energi alternatif yang berasal dari bahan-bahan yang sekiranya tidak bernilai ekonomis
Penggunaan model pembelajaran Problem Solving yang dipadukan dengan metode Numbered Heads Together (NHT) pada mata pelajaran IPA untuk kelas V diharapkan siswa mampu meningkatkan
Berdasarkan dari hasil penelitian dapat disimpulkan : secara simultan, hipotesis yang menyatakan bahwa diduga variable pendidikan dan pelatihan berpengaruh terhadap
Penelitian ini bertujuan untuk mengetahui pengaruh kualitas produk, harga, dan promosi terhadap minat beli konsumen pada Produk Smartphone Nokia dan menganalisiss
