Data Science in the Cloud with Microsoft Azure Machine Learning and Python pdf pdf
Teks penuh
Gambar
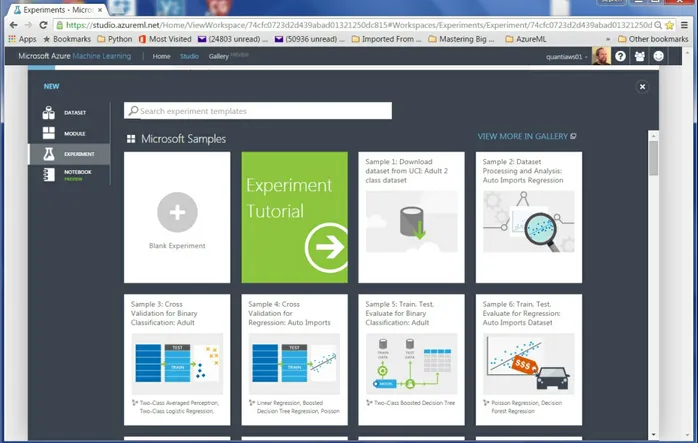
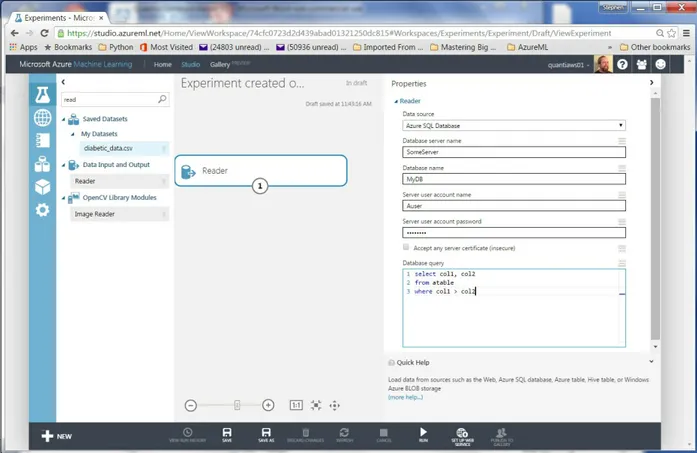
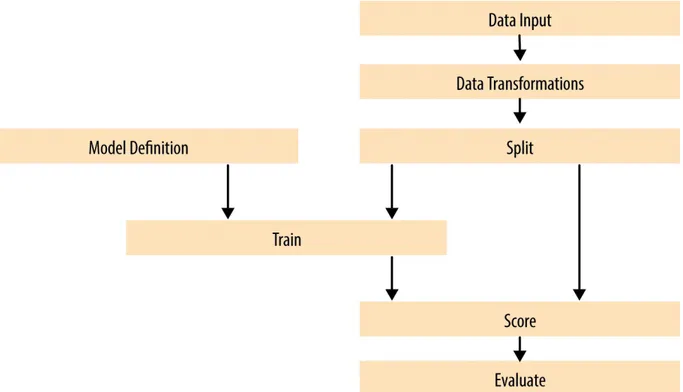
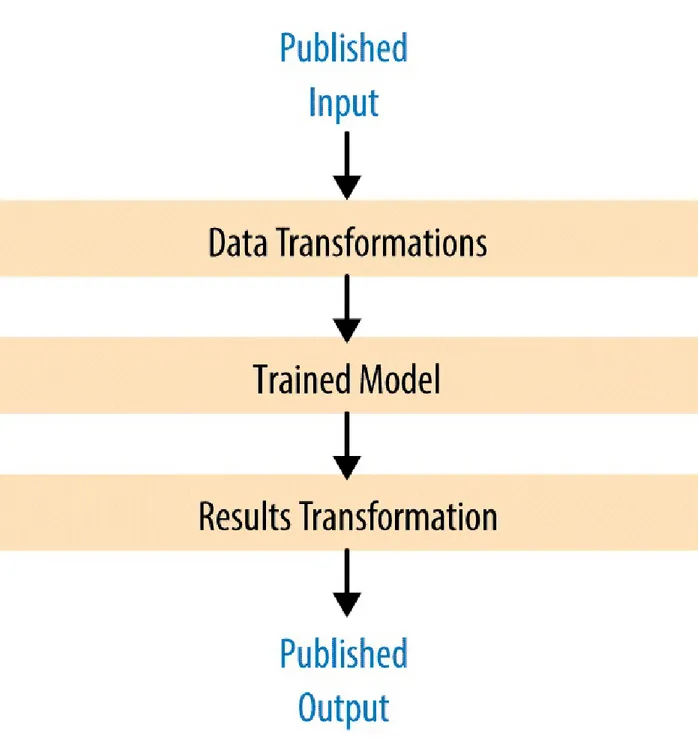
Dokumen terkait
You need to know the content of this book's prequel, Learning IPython for Interactive Computing and Data Visualization: Python programming, the IPython console and notebook,
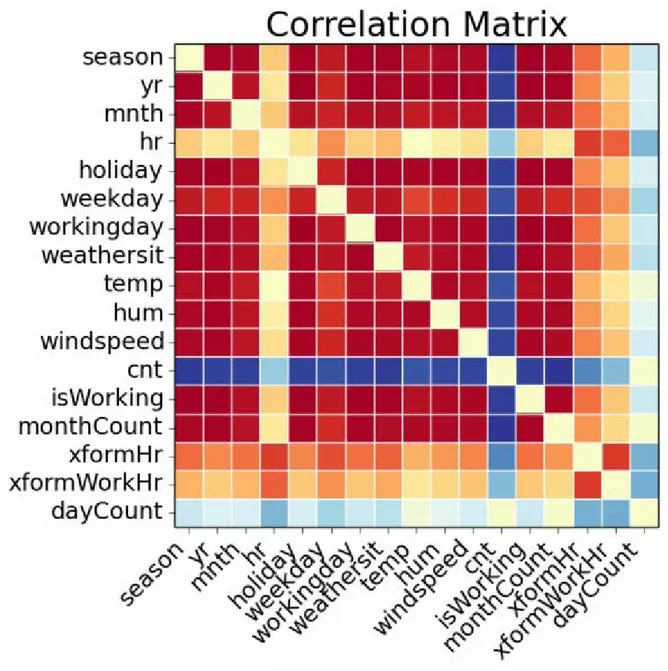
In machine learning, the greater the number of observations and feature sets within the dataset, the greater the likelihood that the model will capture the variability within it, to
Now (if we are using my repository), run the following command to install OpenCV with Python 2.7 bindings and support for depth cameras, including Kinect:.. $ sudo port
He is the author of the IPython Interactive Computing and Visualization Cookbook , Packt Publishing , an advanced-level guide to data science and numerical computing with
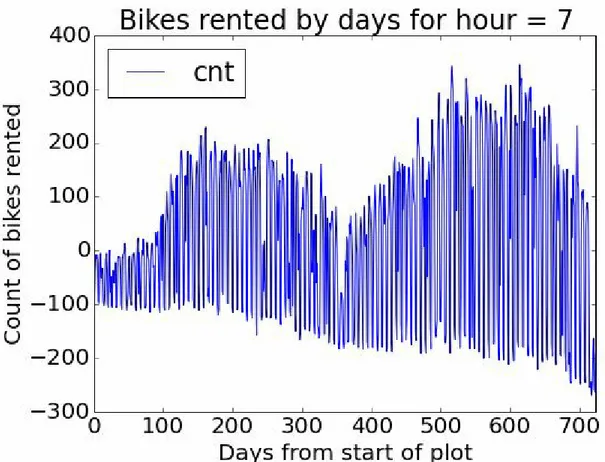
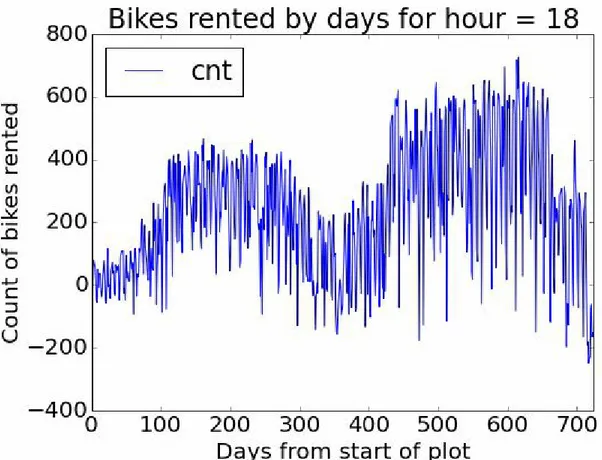
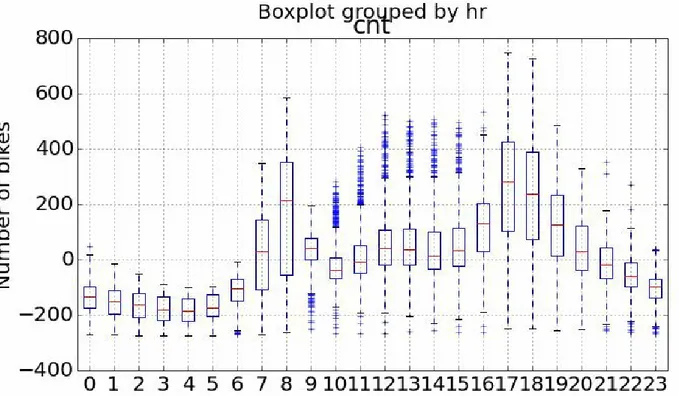
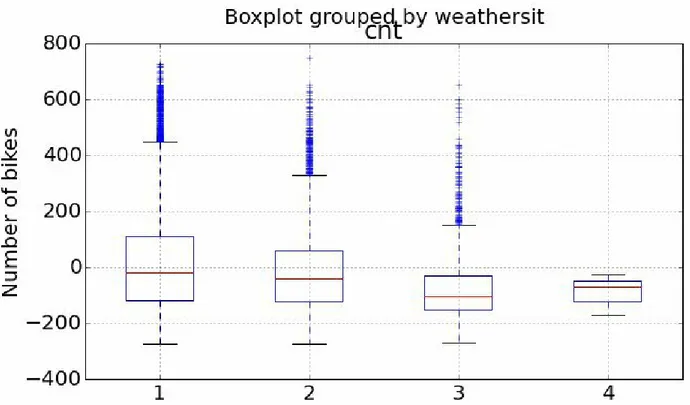
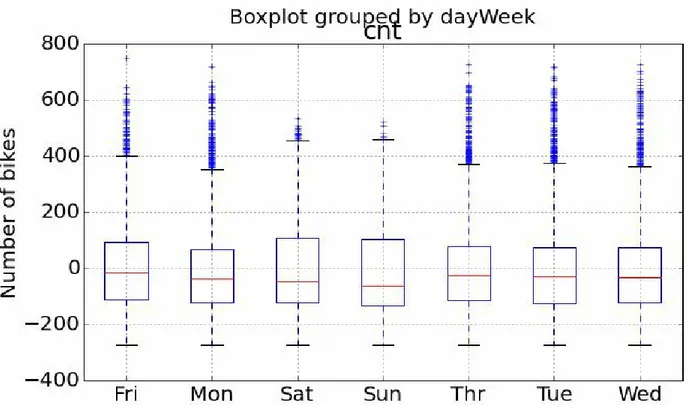
For the first step of this evaluation we’ll create some time series plots to compare the actual bike demand to the demand predicted by the model using the following code:...
$IBQUFS , Debug and Benchmark , takes a comprehensive look at some of the techniques that you can utilize in order to ensure your concurrent Python systems are as free as
We’ll be writing our code using the IDLE program that comes bundled with our Python interpreter.. To do that, let’s first launch the
Approach two In this approach, the recommendation system was built on matrix factorization and the ALS algorithm by utilizing the Apache Spark machine learning library MLlib.. Python
