IMPLEMENTASI METODE HYBRID SALIENCY EXTREME LEARNING MACHINE UNTUK MELAKUKAN SALIENCY DETECTION DALAM SEGMENTASI CITRA
Teks penuh
Gambar

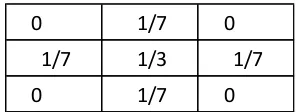
![Gambar 2.3 Kernel Mean Filter Berukuran 3x3 [13]](https://thumb-ap.123doks.com/thumbv2/123dok/1791711.2097201/37.420.175.261.175.259/gambar-kernel-mean-filter-berukuran-x.webp)
![Gambar 2.5 Perbedaan Citra Asli dengan Citra yang Diterapkan Gaussian Filter dengan [15]](https://thumb-ap.123doks.com/thumbv2/123dok/1791711.2097201/39.420.102.332.71.180/gambar-perbedaan-citra-dengan-citra-diterapkan-gaussian-filter.webp)





Dokumen terkait
Sistem Manajemen Mutu berbasis ISO 9001:2008 dibuat untuk mengatur manajemen dalam sebuah organisasi agar lebih terencana dan sistematis agar dapat memenuhi apa
Nama dan logo perusahaan akan dicetak pada barang tersebut, dan banner kecil yang ditempatkan di area simposium. 4 Lanyard (s) 5,000 USD Company name and logo will be
Hasil penelitian menjunjukkan bahwa; (1) pengawasan intern, komitmen organisasi dan pelaksanaan anggaran berbasis kinerja pada Kecamatan Kota Tasikmalaya telah
Panitia/Pokja ULP masih bisa memberikan penjelasan selama 1 jam setelah masa Aanwijzing berakhir Untuk menjawab pertanyaan cukup dengan menyebutkan ID Peserta.. Agregasi Inaproc
pengetahuan baru yang dapat dijadikan sebagai bahan diskusi kelompok kemudian, dengan menggunakan metode ilmiah yang terdapat pada buku pegangan peserta didik atau pada lembar
Bali Mandalaika Tours (Puma Tour) Jl. Hang Tuah Raya, No. Barata Tours & Travel... Jl. Hang Tuah The Grand bali Beacsh
Hasil yang diperoleh dari penelitian ini juga mendukung hipotesis kedua yang diajukan, yaitu jika issuer melakukan manajemen laba, maka penurunan kinerja karena
Dari hasil penelitian yang telah dilakukan, peneliti menemukan bahwa terdapat pengaruh pos- itif penggunaan ekstrak Jeruk Purut terhadap mor- talitas larva Aedes sp,
