KLASIFIKASI STYLE LUKISAN MENGGUNAKAN SELF-ORGANIZING MAPS (SOM)
Teks penuh
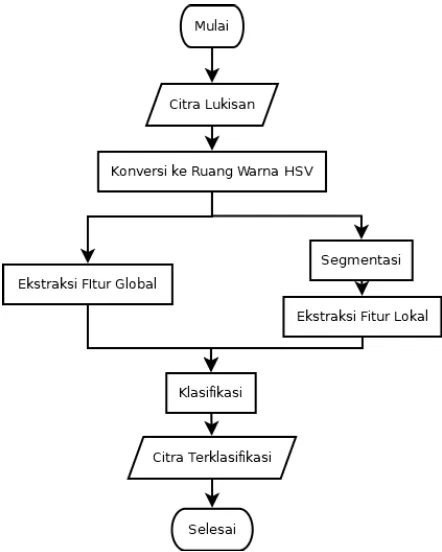
Gambar
![Gambar 2.1 Lukisan ekspresionisme [11]](https://thumb-ap.123doks.com/thumbv2/123dok/1791718.2097205/29.420.115.347.290.478/gambar-lukisan-ekspresionisme.webp)
![Gambar 2.3 Lukisan surealisme [11]](https://thumb-ap.123doks.com/thumbv2/123dok/1791718.2097205/30.420.87.349.277.486/gambar-lukisan-surealisme.webp)



Dokumen terkait
X 2 terhadap Y.... Surat Izin Penelitian ... Surat Keterangan telah Melakukan Penelitian dari SMK Negeri 1 Kalasan ... Surat Keterangan telah Melakukan Penelitian dari SMK Negeri
Fatmariani, F., 2013, “Pengaruh Struktur Kepemilikan, Debt Covenant , dan Growth Opportunities terhadap Konservatisme Akuntansi pada Perusahaan Manufaktur
Seberapa jauh perusahaan asuransi bertanggung jawab bilamana terjadi kerusakan atau kehilangan barang serta kerugian lainnya (termasuk jumlah maksimum pembayaran ganti rugi)
n. menentukan SN berdasarkan hasil langkah 14. Jika nilai SN mendekati nilai SN yang diasumsikan untuk menghitung angka ekivalen, maka perencanaan tebal lapis perkerasan
Berdasarkan hasil analisis data menunjukan bahwa kinerja lingkungan dan pengungkapan lingkungan berpengaruh terhadap kinerja keuangan pada perusahaan sektor barang
Hasil penelitian menunjukkan bahwa: 1)Volume perdagangan saham pada periode publikasi tidak lebih tinggi dari di luar periode publikasi laporan arus kas, hal
Selisih rerata nilai Vertical jump sebelum dan sesudah perlakuan pada kelompok LZZ adalah 6,125 dengan simpangan baku 2,416 Hasil perhitungan paired samples t-test
Mengingat pentingnya dalam mencapai pembangunan ekonomi disektor perikanan terutama perikanan tambak diantara sektor-sektor yang lain maka penelitian ini mencoba menganalisa dan
