APLIKASI PERBAIKAN EJAAN PADA KARYA TULIS ILMIAH DIPROGRAM STUDI TEKNIK INFORMATIKA DENGAN MENERAPKAN ALGORITMA LEVENSHTEIN DISTANCE
Teks penuh
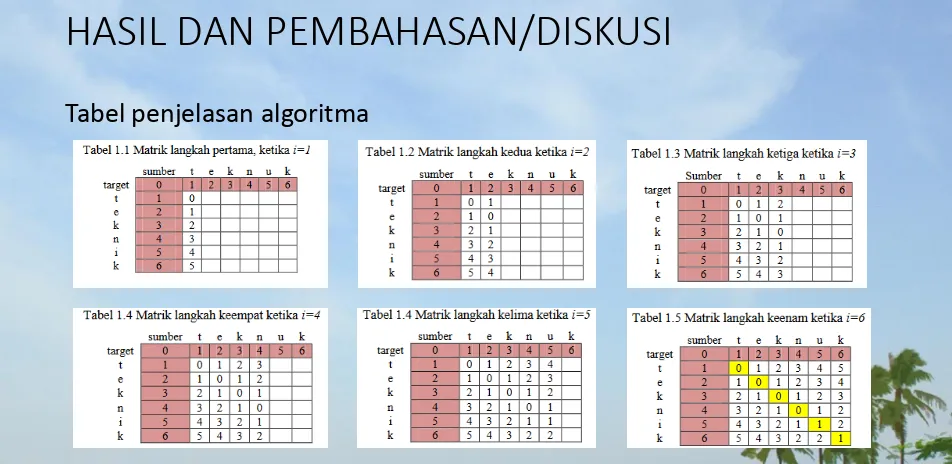
Gambar

Dokumen terkait
Proses kontak pertama kali ditemukan pada tahun 1831 oleh Phillips, seorang Inggris, yang patennya mencakup aspek – aspek penting dari proses kontak yang modern, yaitu
Pembelajaran tiga ragam gerak tari di SMP LB PKK SUKARAME tahun pelajaran 2012/2013 dapat diketahui hasil belajar siswa pada setiap aspek, aspek yang pertama
Kelayakan media pembelajaran materi membuat pola celana pria berbasis Adobe Flash yang digunakan dalam proses pembelajaran pada kelas XI di SMK Negeri 2 Godean
Kerenyahan yang dipilih oleh panelis yaitu pada sampel F4 yang memiliki formulasi tepung tapioka 50%, tepung kacang merah. 40% dan tepung konjac
Perlu dilakukan penelitian lebih lanjut agar didapatkan pengurangan telur yang lebih besar dari 40% dengan menggunakan konsentrasi gum xanthan yang tepat pada
lurus dengan nilai biokamulasi Pb yang dilakukan oleh tanaman Liu et al., (2008) menyatakan bahwa konsentrasi Pb pada bagian pucuk lebih rendah daripada bagian akar dan
dengan mata atau mikroskop optik; r didefinisikan sebagai rasio antara luas permukaan yang sebenarnya dengan daerah hasil proyeksi dan sebagai faktor kekasaran yang
list simpul dan bagian sisi yang disebut dengan list sisi. List simpul adalah list yang yang anggotanya merupakan elemen-elemen simpul/ nodes penyusun graf. Setiap Objek dari
