MODEL DATA MINING DALAM PENGKLASIFIKASIAN KETERTARIKAN BELAJAR MAHASISWA MENGGUNAKAN METODE CLUSTERING
Teks penuh
Gambar
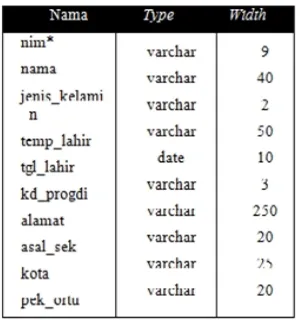
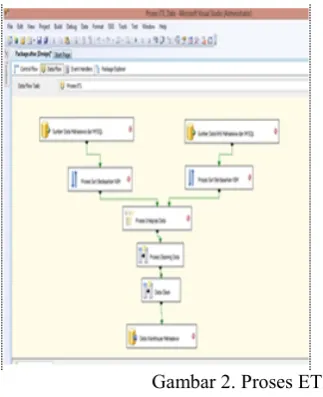
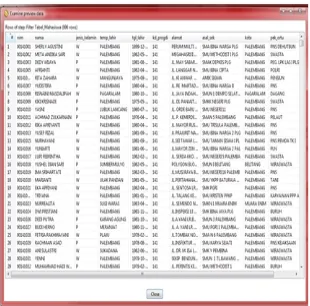
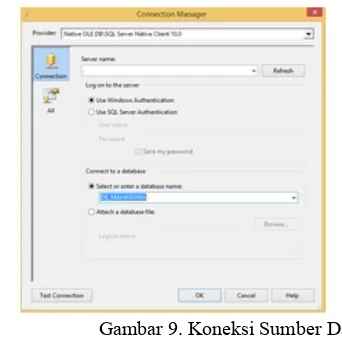
Dokumen terkait
Tahun 2014.. 10) Silakan tambahkan poin selanjutnya jika masih diperlukan. Bagaimana pendapat Anda mengenai tanggapan dari pengelola Program Studi D-IV Kearsipan
Penelitian ini dapat menjelaskan bahwa siswa yang mempunyai kreativitas tinggi dan sikap ilmiah tinggi jika diajar menggunakan model POE dengan metode proyek
Pelebaran jalan raya studi kasus jalan Teuku Umar di Kota Bndar lampung adalah salah satu alternatif pemecahan masalah yang dipilih pemerintah provinsi lampung guna
Skripsi dengan judul “ Pengaturan Penyelesaian Sengketa Melalui Arbitrase Secara Online di Indonesia ” ini bertujuan untuk dapat mengetahui bagaimana ketentuan
Oleh sebab itu, peneliti tertarik untuk melakukan analisis lebih dalam lagi dengan mengajukan judul Pengaruh Struktur Kepemilikan Manajerial dan Institusional Terhadap
Menurut Salahudin (Ustadz) bahwa apabila santri ada yang bermasalah, penanganannya tidak langsung ke pengasuhan namun tetap kami kontrol melalui wali asuh, jadi wali asuh
Hasil penelitian menunjukkan bahwa dengan penerapan brand image pada produk bulog di Perum Bulog Divre Sulselbar memiliki manfaat pada setiap produk dengan kata
Pada bayi kurang bulan yang mendapat susu formula juga akan mengalami peningkatan dengan puncak lebih tinggi dan lebih lama, demikian juga penurunannya jika tidak
