Troubleshooting BGP A Practical Guide to Understanding and Troubleshooting BGP pdf pdf
Bebas
835
0
0
Teks penuh
Gambar
+7
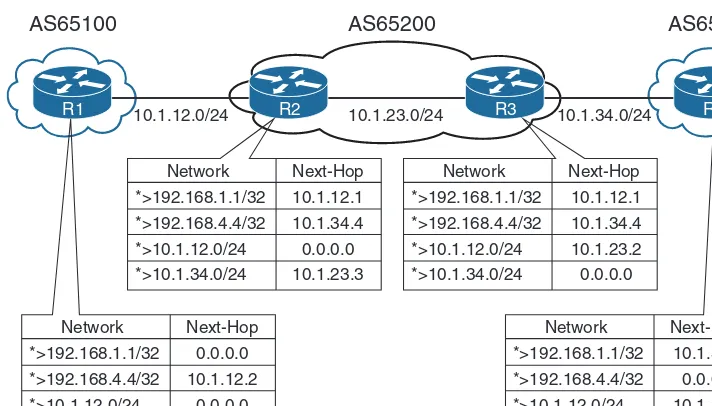
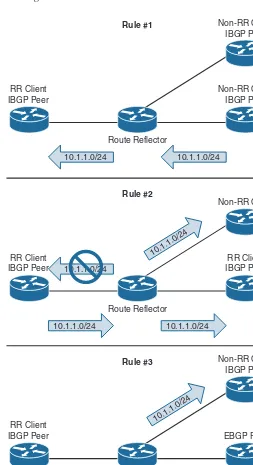

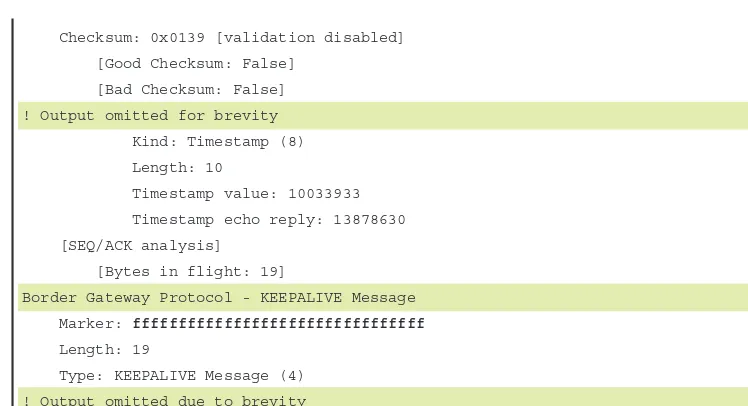
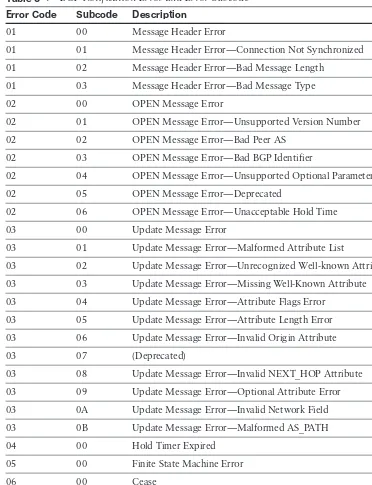
Dokumen terkait
Chapter 7 shows you how to create a new modification (also known as a hack) for yourself, to help you get that extra feature you are so missing. In this chapter, you will start
