Big Data For Dummies 2010kaiser pdf pdf
Teks penuh
Gambar

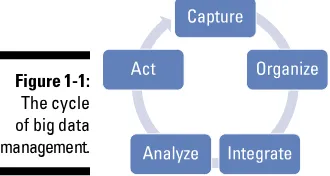
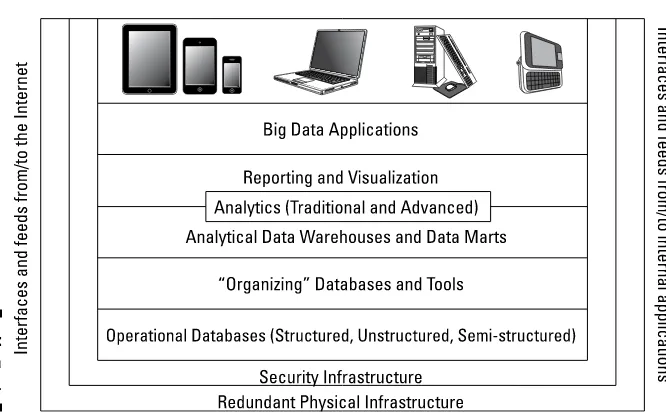
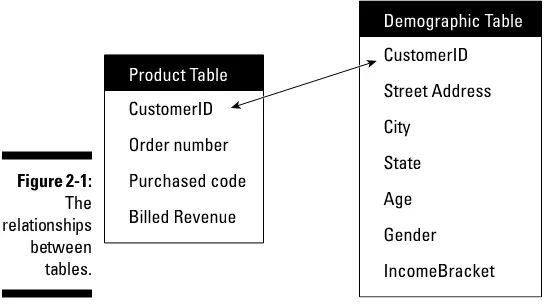
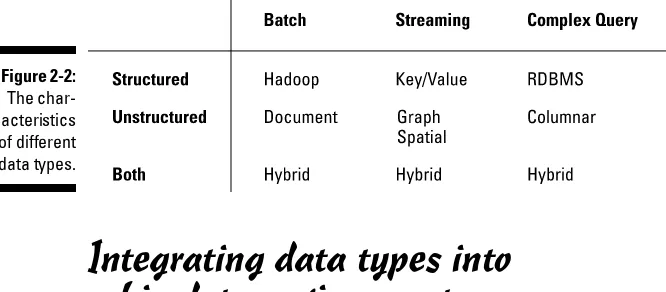
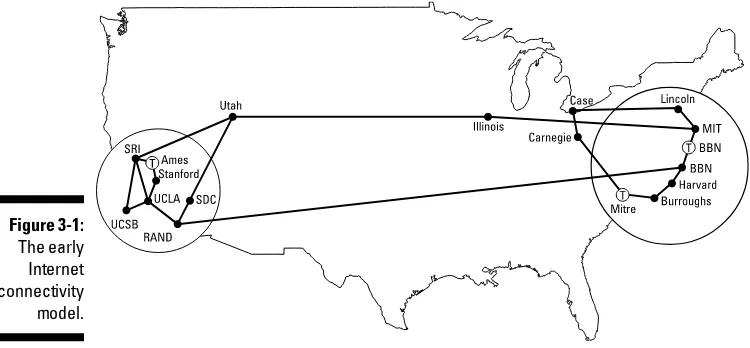
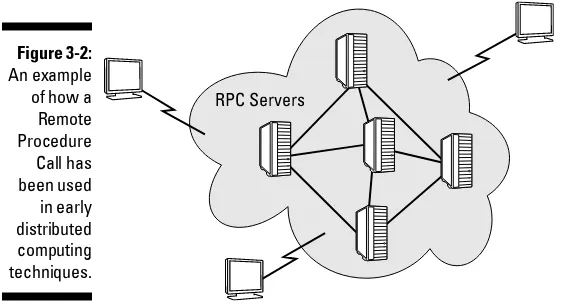
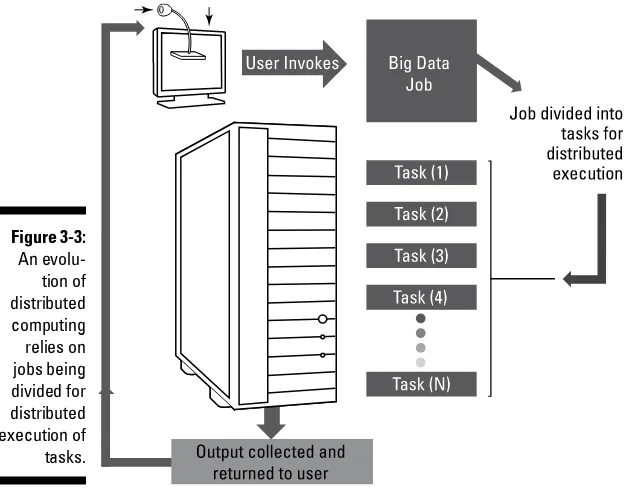
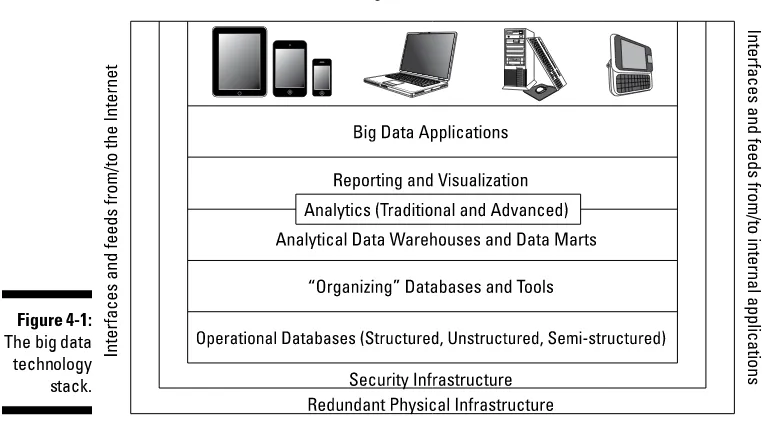
Garis besar
Dokumen terkait
Both of subcutaneous and intraperitoneal ways will interact systematically in the body, so that increasing width of lung connective tissue due to Bleomycin application
Table 3.. The body size also describes the uniqueness of the SenSi-1 Agrinak chicken as male line of native broiler chicken. Table 6 presents adult body weight and
It can be concluded that this research collected quantitative data and used statistical formula to measure whether or not there is a significant difference between writing ability
Hasil terbaik yang di peroleh dari pengambilan lignin pada batang rumput gajah ini di hasilkan oleh pelarut dengan konsentrasi 6% pada waktu 6 jam yang menghasilkan randemen sebanyak
Penelitian ini bertujuan untuk mengetahui pengaruh corporate social responsiblity terhadap citra perusahaan dan berdampak pada minat beli konsumen Yamaha Vega ZR New di
status bahan organik tanah (Sudirman dan Vadari 2000; Kurnia et al. 2005), sehingga perbaikan status bahan organik harus menjadi priorias dalam pemulihan lahan
Dari hasil pengelompokan tersebut dipilih kelompok karakter yang hasil pengelompokannya mendekati pengelompokan berdasar total karakter, sehingga untuk selanjutnya dapat
Sistem Informasi Eksekutif adalah sistem yang dibuat hanya untuk digunakan oleh kepala perpustakaan. Permasalahan yang dihadapi adalah banyaknya data yang terdapat didalam
