Big Data Computing Ebook free download pdf pdf
Teks penuh
Gambar
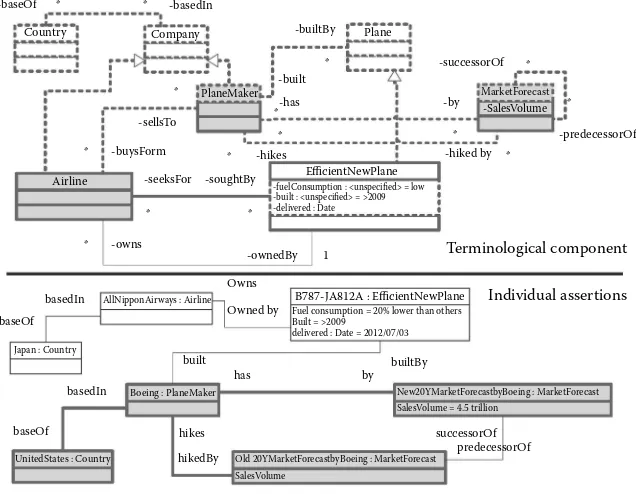
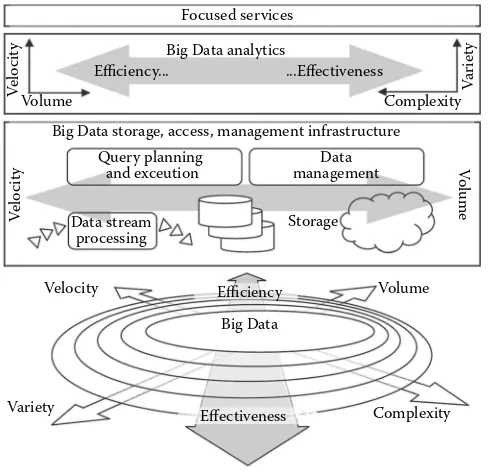

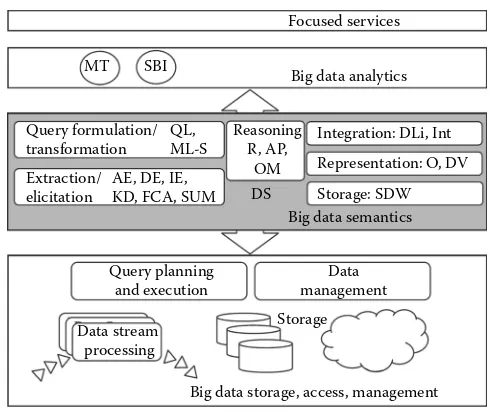

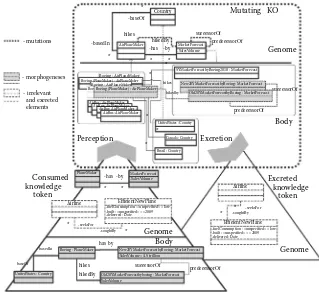




Garis besar
Dokumen terkait
Setelah diberi layanan orientasi pada sikus I, aktivitas belajar terhadap penggunaan internet peserta didik meningkat tetapi belum maksimal dengan rata-rata
Hasil penelitian yang dapat di simpulkan adalah pembagian waris menurut hukum Islam dan Kitab Undang-Undang Hukum Perdata sangat berbeda baik itu secara prinsip maupun
mempertimbangkan lingkungan dimana lokasi itu berada. Dekat dengan pusat kota atau perumahan, kondisi lahan parkir, lingkungan belajar yang kondusif dan transportasi.
Prestasi belajar adalah hasil yang diperoleh dari suatu ativitas baik individu maupun kelompok yang mengakibatkan perubahan tingkah laku untuk kemajuan individu
(diameter 2-5 mm) dari tujuh varietas yang dapat menghasilkan umbi mini dengan nisbah perbanyakan berkisar 6,07 (Cipanas) dan 13,22 (Merbabu) ditunjang dengan teknik produksi
Adanya komunikasi dan partisipasi pemakai dalam pengembangan sistem informasi akuntansi diharapkan dapat mendesain suatu sistem yang mampu bekerjasama dengan pemakai
Kendala utama sistem produksi sayuran di rumah plastik menurut persepsi responden berdasarkan peringkat kepentingannya, secara berturut-turut adalah insiden hama penyakit,
Berdasarkan pengertian model pembelajaran kooperatif dapat diambil kesipulan bahwa model pembelajaran kooperatif adalah model pembelajaran yang menekankan pada aspek sosial
