serverless ops a beginner guide to AWS lambda and Beyond pdf pdf
Teks penuh
Gambar

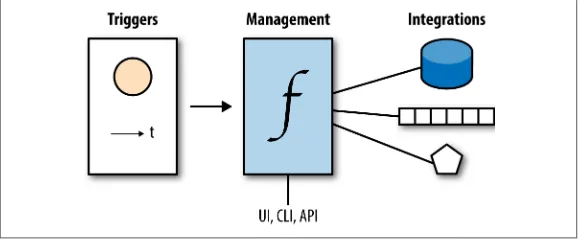
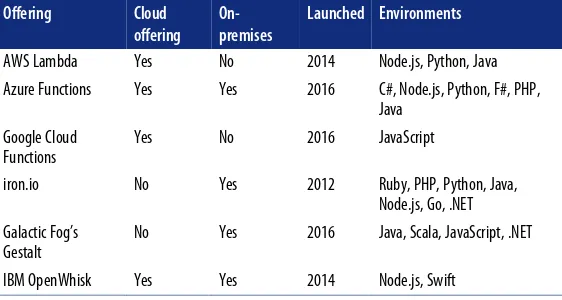
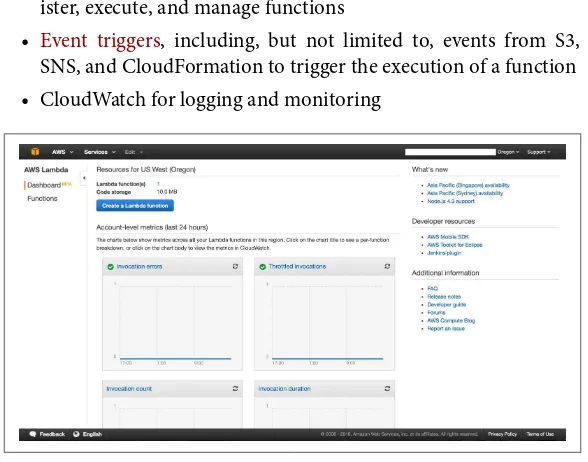
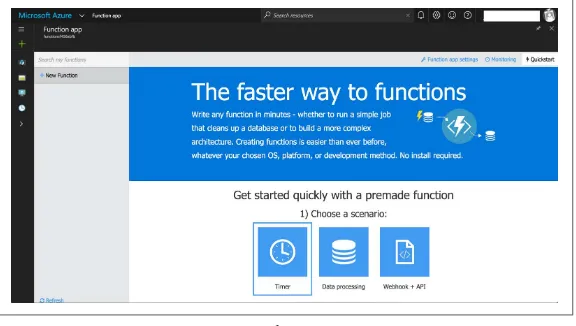
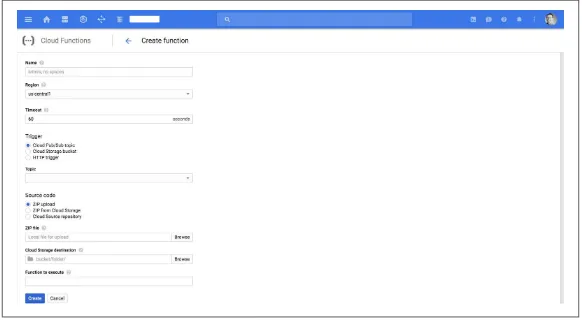
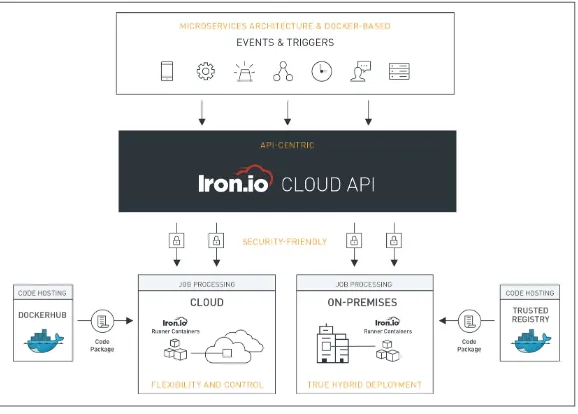

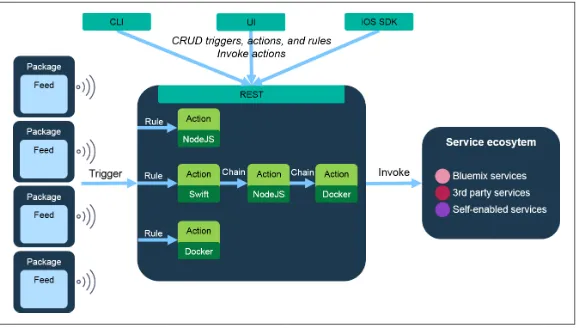
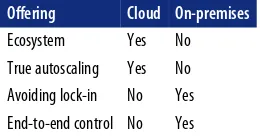
Dokumen terkait
Deskripsi Hasil Penguasaan Nomina Bahasa Jerman Siswa Setelah Penggunaan Teknik Permainan Der Groβe Preis .... Deskripsi Keefektifan Teknik Permainan Der Gro β e Preis
Maka dengan surat ini kami selaku Badan Pendidikan Sekolah, bermaksud mengadakan studi lapangan bagi siswa siswi baik IPA maupun IPS di
Pendaftaran dan pengambilan dokumen oleh direktur atau diwakilkan dengan menyerahkan surat kuasa dan surat tugas dari direktur2. Satu orang hanya dapat mewakili 1 (satu)
Mata kuliah ini mengarahkan mahasiswa untuk membantu mahasiswa dengan berbagai hal yang berkaitan dengan bermain dan permainan anak yang mencakup manfaat, karakteristik, dan
• No ponto 10 indique o montante total de impostos sobre os rendimentos pagos ao SRTL durante o ano 2005. • No ponto 20 indique o montante total de impostos sobre os
Diharapkan dapat menambah pengetahuan para pelajar kelas XI SMA Negeri 2 Yogyakarta tentang kesehatan reproduksi remaja khususnya tentang perilaku seks bebas dan bahaya
Untuk menghasilkan padi/beras dan bahan pangan lainnya pada tingkat kecukupan kebutuhan konsumsi domestik (taraf swasembada pangan nasional) dari tahun 2010 sampai dengan
Sejalan dengan fenomena penurunan swasembada beras, pemerintah perlu mengubah kebijakan harga pangan pokok dari beras ke nonberas. Namun masalah- nya petani palawija masih
