Creating your MySQL Database Practical Design Tips and Techniques pdf pdf
Teks penuh
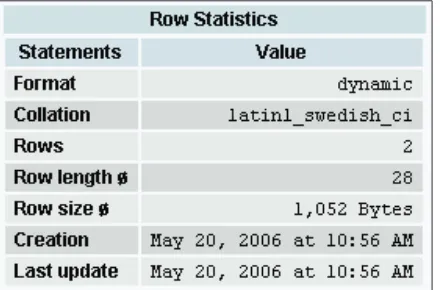
Gambar

Dokumen terkait
Di dalam suatu perusahaan baik itu bergerak di bidang jasa maupun manufaktur, selalu terdapat banyak kemungkinan, salah satu diantaranya adalah kondisi dimana
agencies to participate in the provision of education, to establish and manage schools and other educational institutions at all levels. ☺ Identification of critical priority areas
PERBAND INGAN WAKTU AKTIF BELAJAR SISWA ANTARA PROSES BELAJAR MENGAJAR FUTSAL IND OOR D ENGAN OUTD OOR PAD A SISWA SMAN 1 TASIKMALAYA.. Universitas Pendidikan Indonesia
52) The European corn borer is an insect whose larvae eat corn crops, thus reducing the yield of the crops. Scientists have genetically modified corn in the hopes of making it
Sistem akad perjanjian kredit pada PT Colombus Pinrang yaitu dengan cara pihak pertama melampirkan foto copy Kartu Keluarga (KK) dan foto copy Kartu Tanda
Secara khusus, penulisan ini bertujuan untuk mengetahui karakteristik dadih susu sapi melalui modifikasi sifat susu agar menyerupai sifat susu kerbau, mengaplikasikan mikroba
Sebagaimana ungkapan Midgley (1995) bahwa pembangunan sosial adalah proses pembangunan yang direncanakan dan diselaraskan dengan pembangunan ekonomi yang bertujuan untuk
mal<a dengan ini diumumkan dafur pendek (shott lisl hasil evaluasi kualifil€si dan pembuktian. kualifiI@si pengadaan tersebut diatas, *bagai
