Semi-Automatic Video Object Extraction Menggunakan Alpha Matting Berbasis Motion Estimation - ITS Repository
Bebas
130
0
0
Teks penuh
Gambar
![Gambar 1.1. Hasil segmentasi pada natural image[11].](https://thumb-ap.123doks.com/thumbv2/123dok/1784646.2095810/21.595.153.464.529.681/gambar-hasil-segmentasi-pada-natural-image.webp)
![Gambar 1.2. Sistem segmentasi video [14].](https://thumb-ap.123doks.com/thumbv2/123dok/1784646.2095810/24.595.173.482.332.668/gambar-sistem-segmentasi-video.webp)
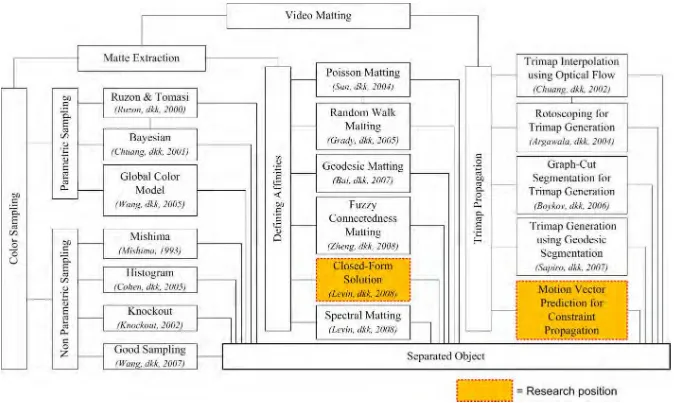
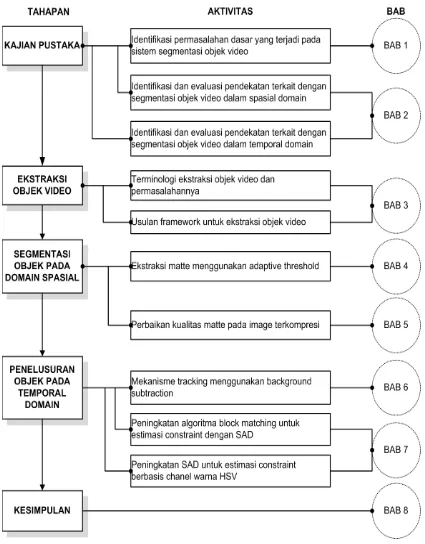
+7
![Gambar 2.1. Objek video dalam komunikasi visual [17].](https://thumb-ap.123doks.com/thumbv2/123dok/1784646.2095810/35.595.117.509.485.712/gambar-objek-video-dalam-komunikasi-visual.webp)

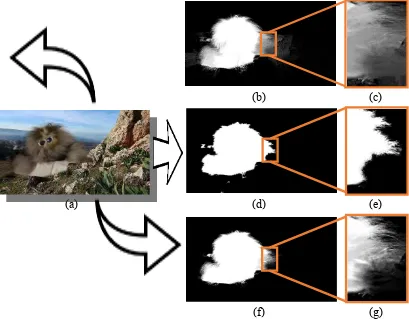
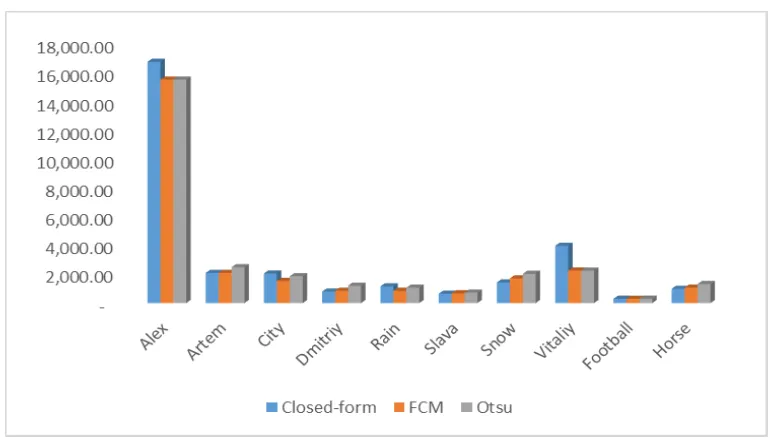
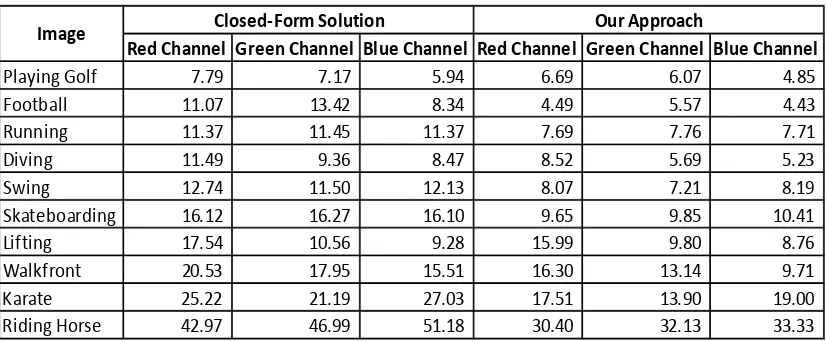
Dokumen terkait
