Hadoop Illuminated Ebook free download pdf pdf
Teks penuh
Gambar

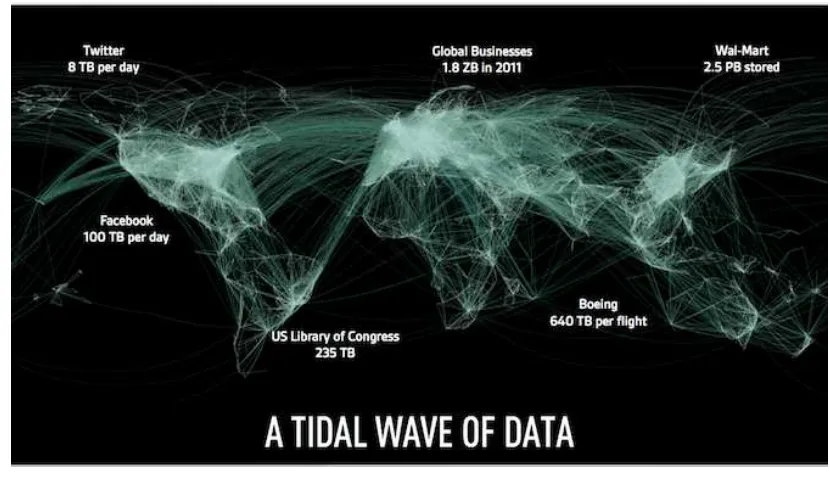

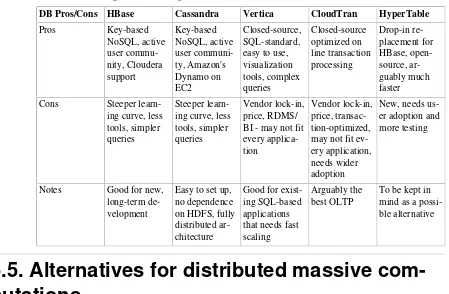
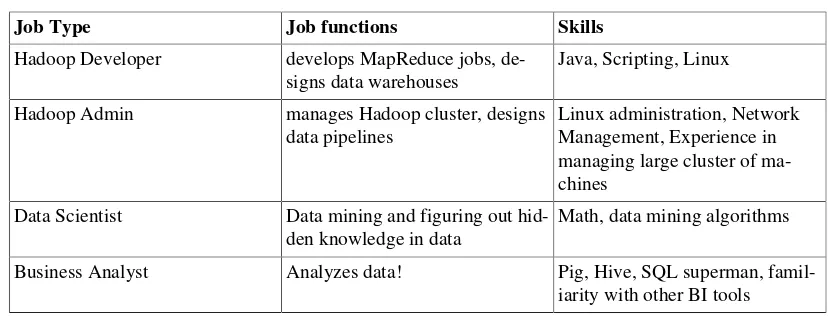

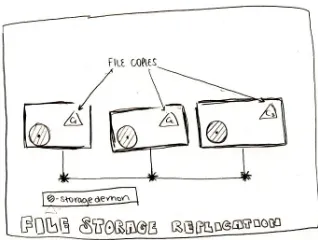
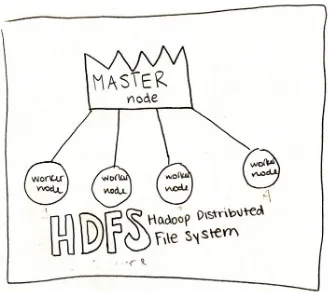
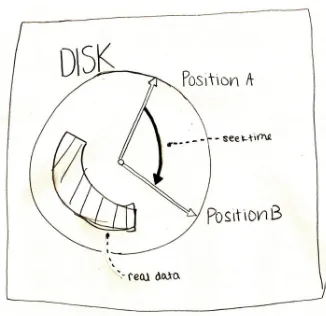
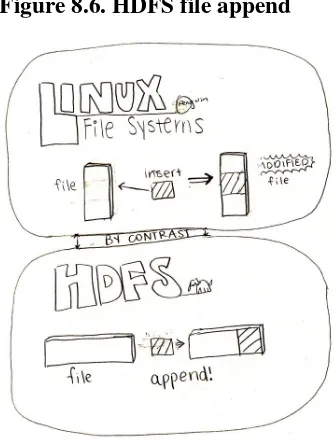
Garis besar
Dokumen terkait
Tujuan yang ingin dicapai dari penelitian ini adalah meneliti kemampuan biofilter aerob menggunakan media batu tembikar sebagai media biofilter dalam menurunkan
Berdasarkan uji korelasi matriks, diperoleh gambaran secara umum bahwa di daerah penelitian, KTK tanah berhubungan erat dengan karbon organik, kadar liat total, oksida besi, dan
As a result of this development, quantitative rainfall forecasting, such as numerical weather prediction, becomes as main input in crop simulation, especially for water
Secara teoritis dibedakan konflik kepentingan ( conclict of interrest ) dan kalim atas hak ( claim of rights ). Sedang Nader dan Todd membedakan keduanya dengan
Selain oleh PPID Perpustakaan Nasional RI, pelatihan perpustakaan juga banyak diselenggarakan oleh perguruan tinggi dan lembaga pemerintah lainnya, seperti: (1) Program
1. Siswa memperhatika guru yang sedang menyampaikan tujuan pembelajaran.. dengan melibatkan satuan baku dengan benar dan tepat. Guru meminta siswa membuka buku paket
Langkah awal dengan memberikan pretest untuk masing-masing kelompok, yaitu siswa kelas V SD Negeri Polobogo 02 sebagai kelompok eksperimen dan siswa kelas V SD
(3) Perlu di lakukan penambahan petugas di areal parkir, untuk menambah keamanan serta fasilitas papan petunjuk keseluruh fasilitas wisata yang ada di Agrowisata Rembangan,
