Addison Wesley The Object Oriented Thought Process 3rd Edition Sep 2008 ISBN 0672330164 pdf
Teks penuh
Gambar

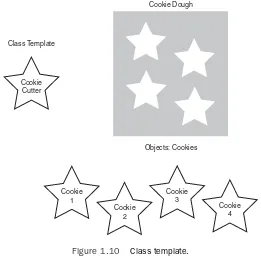
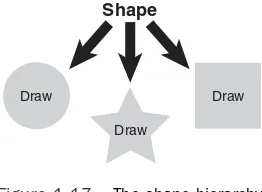



Dokumen terkait
Demikian Penetapan Pemenang dibuat untuk dapat dipergunakan sebagaimana mestinya. Pekerjaan : PENYUSUNAN
Penelitian ini bertujuan untuk mengetahui jenis tanaman dominan dan membandingkan tanaman dominan, mengetahui hubungan antara tanaman dominan terhadap indeks kesuburan
Kultivar pisang yang dapat ditemukan di seluruh wilayah Kecamatan Wates adalah pisang kepok kuning, pisang kepok hijau, pisang kepok gabu, pisang ambon kuning, pisang ambon
"جنوجا جنولوت وجاويوب يلا كيتيب اهتبتك ديقلا رفدلا مقر ،اافليس. 1721143086 .ةجاحا ،رتسجاما ،ةـيسم اد يإ ،فرشما ، ةيسيئارلا تاملكلا : يف ت تافاقثلا
2.5 Tujuan penerapan manajemen berbasis nilai.. Sebuah nilai organisasi bersama membentuk budaya organisasi dan mempengaruhi cara organisasi beroperasi, kehidupan perusahaan
Kerusakan lahan terjadi di semua jenis kawasan lindung mulai dari hulu sampai ke hilir, mulai dari tingkat kerusakan ringan sampai dengan berat. sempadan pantai,
This Consensus Study Report Highlights was prepared by the National Academies of Sciences Engineering, and Medicine, based on the Consensus Study Report Microbiomes of the Built
bahwa berdasarkan pertimbangan sebagaimana dimaksud dalam huruf a dan huruf b serta untuk melaksanakan ketentuan Pasal 4 ayat (4) Undang-Undang Nomor 19 Tahun
