467 Adobe ColdFusion Anthology free download ebook
Teks penuh
Gambar
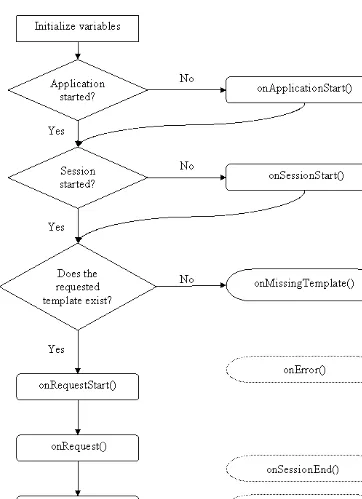
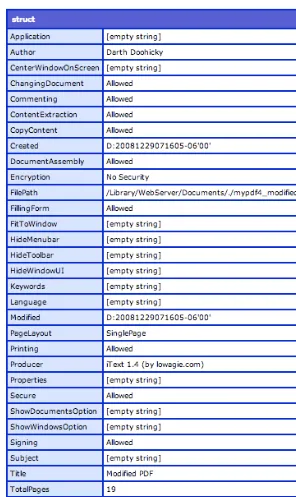

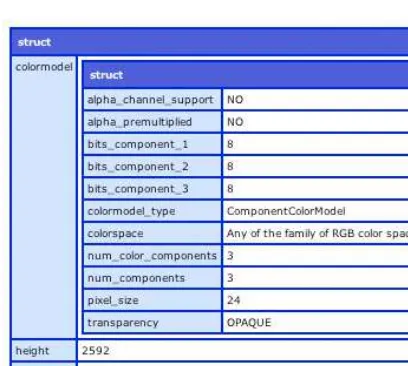
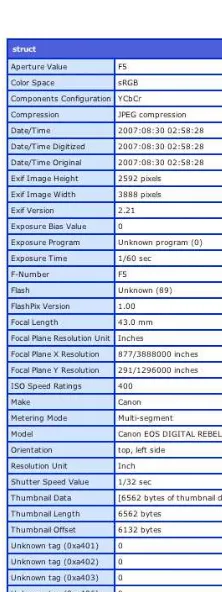



Dokumen terkait
Metode penelitian kuantitatif diartikan sebagai metode penelitian yang berlandaskan pada filsafat positivisme, digunakan untuk meneliti pada populasi atau sampel
Dengan mengucapkan rasa syukur kepada Tuhan Yang Maha esa dan dengan segala rahmat serta karuniaNya sehingga penyusun telah dapat menyelesaikan Tugas Akhir “Pra
Beberapa faktor yang umum termasuk salah satunya adalah proses pengajaran serta kurang variatifnya membuat sebagian besar para pelajar merasa jenuh. Sehingga hal ini
strategies and skill can help students complete their writing tasks successfullyD. Writing strategies are applied in the process of
Tahap ketiga yaitu perpanjangan atau ekstensi fragmen DNA dengan enzim polimerase dan primer untuk menghasilkan kopi DNA yang dapat berungsi sebagai DNA cetakan
Segenap Dosen Fakultas Psikologi Universitas Katolik Soegijapranata Semarang yang telah memberikan pengarahan dan nilai-nilai hidup selama penulis menjalani studi di
mengacu pada SNI 03-6572-2001.Secara umum perencanaan ini dimulai dari menentukan jumlah penerangan ruangan, beban pendinginan, luas penghantar kabel, pengaman,
Sejak awal perkembangan akuntansi telah dibalut dengan strategi meningkatkan perekonomian dalam negeri dengan mengundang masuknya investor asing sehingga pada tahun
