in search of database nirvana pdf pdf
Teks penuh
Gambar
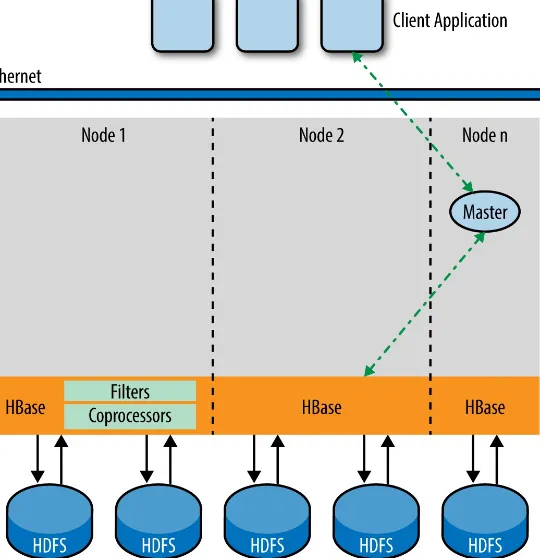
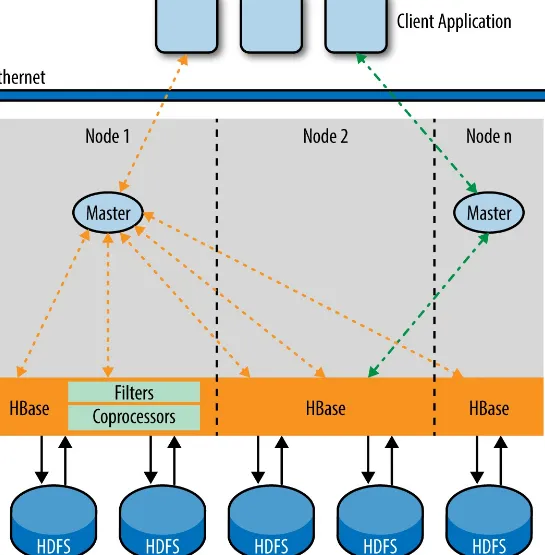
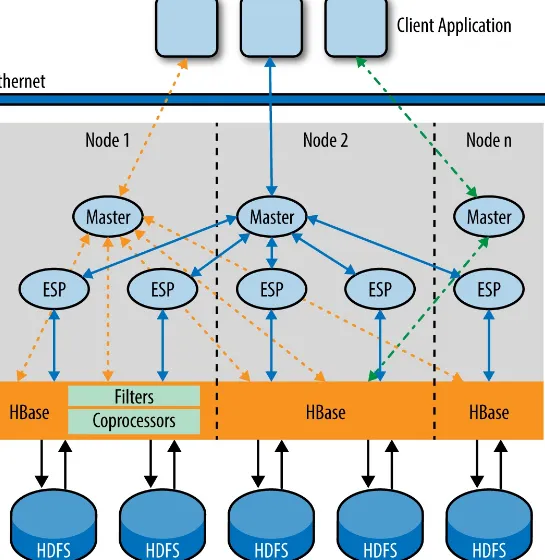

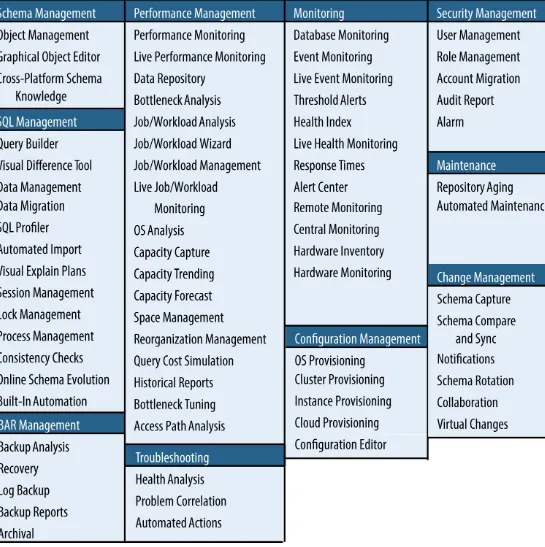
Garis besar
Dokumen terkait
Tujuan umum dari pelaksanaan Praktik Pengalaman Lapangan (PPL) ialah membentuk mahasiswa praktikan agar menjadi calon tenaga kependidikan yang.. profesional, sesuai
Hasil analisa dengan metode AHP terhadap kuesioner pada 6 orang responden yang merupakan stakeholders yang terdiri dari wakil perencana program, wakil pelaksana
Metode penelitian kuantitatif dapat diartikan sebagai metode penelitian yang berlandaskan pada filsafat positivisme, digunakan untuk meneliti pada populasi atau
Penerapan Teknik Self Monitoring Untuk Mereduksi Perilaku Agresif Anak Hambatan Emosi D an Perilaku.. Universitas Pendidikan Indonesia | repository.upi.edu |
Jika garis pada satu himpunan dengan himpunan lainnya tidak ada yang sejajar dan tidak ada 3 garis berpotongan di titik yang sama, maka jumlah titik perpotongan yang
Pengembangan tanaman kopi arabika di wilayah nagori Sait Buttu Saribu, Kecamatan Pamatang Sidamanik, Kabupaten Simalungun sudah dilakukan oleh masyarakat petani kopi sejak
• Setelah bahan pustaka diterima dan bahan pustaka tersebut diterbitkan oleh UK/UPT sendiri dan bukan dalam bentuk publikasi berkala ilmiah maka pengelola informasi/pustakawan
Penghayatan amalan moral dan akhlak yang baik dalam kalangan pelajar diharap dapat merealisasikan matlamat pendidikan negara serta mencapai salah satu hasrat
