Cisco CCNA in 60 Days Learn to Master the Hands On Labs, Ace Technical Questions and Pass the CCNA 2nd Edition pdf pdf
Bebas
808
0
0
Teks penuh
Gambar

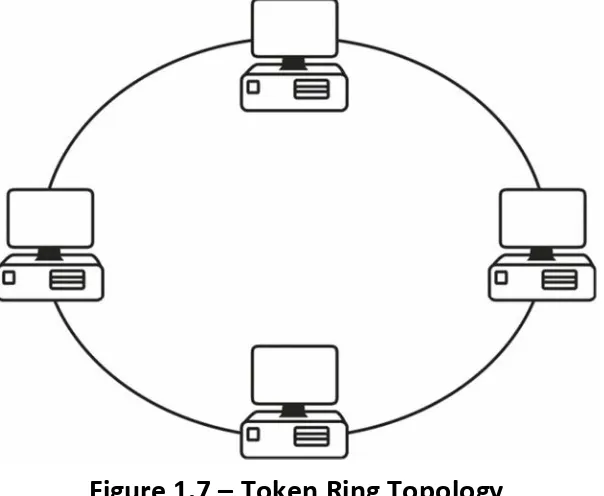
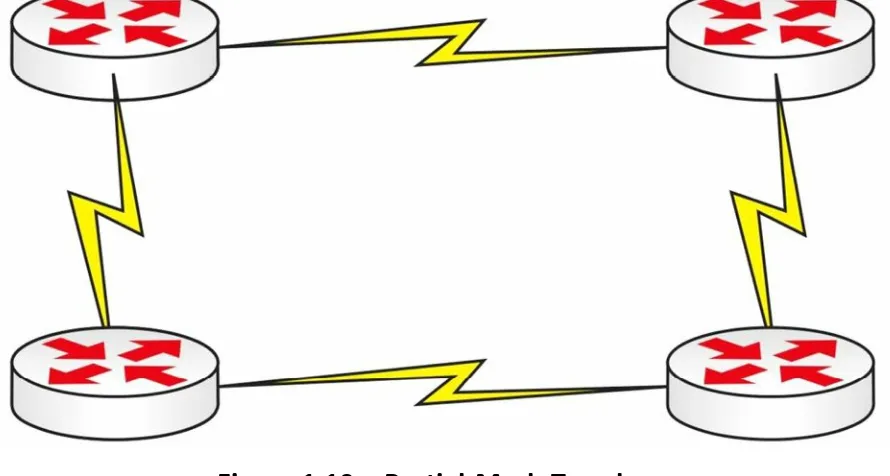
+7

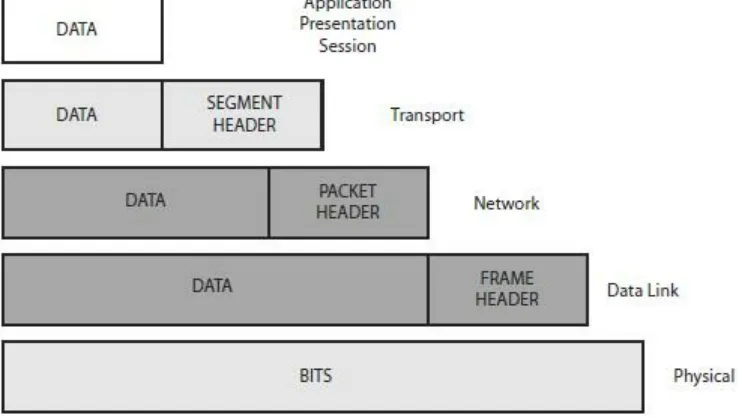
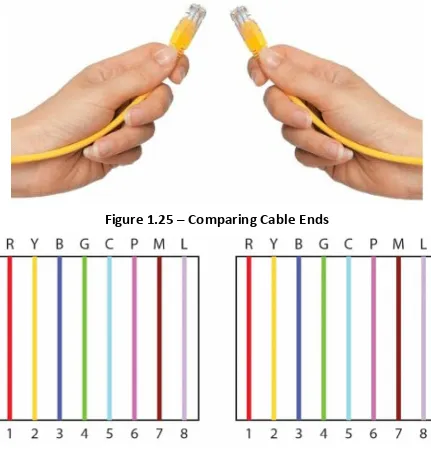
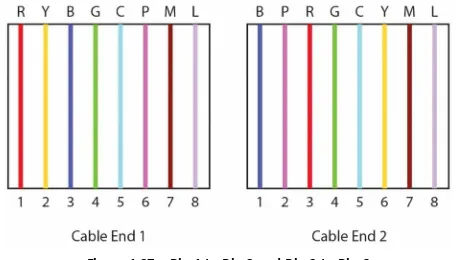


Dokumen terkait
