Python for Data Science For Dummies pdf pdf
Teks penuh
Gambar
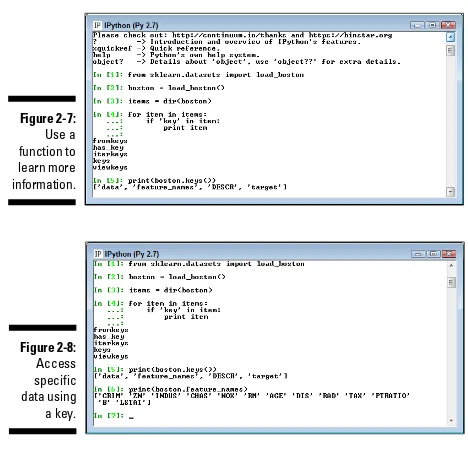
Garis besar
Dokumen terkait
Kemampuan dasar komunitas pada pemrograman python sudah sangat baik dengan nilai rata-rata pemahaman variabel python pada saat pretest mencapai angka 75.2 yang
the sample data and scripts, use a line of Python code to call the Buffer tool and generate buffers around the input features with the following steps:.. When you preview the fi
Remember: The interview isn’t just a chance for the interviewers to determine if they want to hire you — it’s also an opportunity for you to determine if this is the company
You need to know the content of this book's prequel, Learning IPython for Interactive Computing and Data Visualization: Python programming, the IPython console and notebook,
As you are saving things on Python, you will be able to save this file on a disk, but you can also make sure that you are reusing the code over again, as many times as you would
When you respond to an e-mail, Outlook Express will automatically add that person and e-mail address to your Address Book if you do the following: Choose Options from the Tools
Every account you add will almost always be associated with one or more contacts (people), so you’ll find it easier to create the contact records before you create the account
If you work with a carrier company that supports VoIP-based telephony, and a hardware vendor that provides hardware to support both types of networks, you can enjoy your conversion
