[Bookflare net] Big Data and Machine Learning in Quantitative Investment pdf pdf
Teks penuh
Gambar
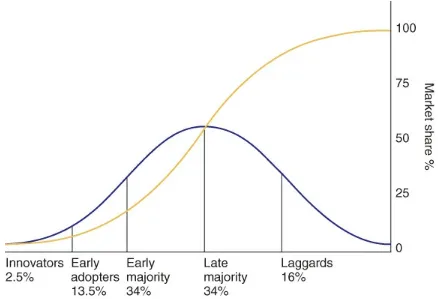
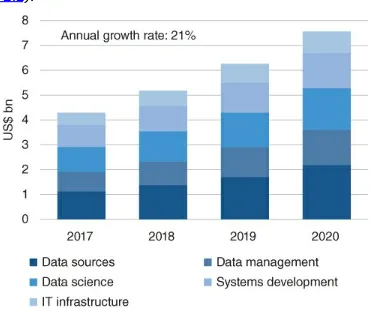

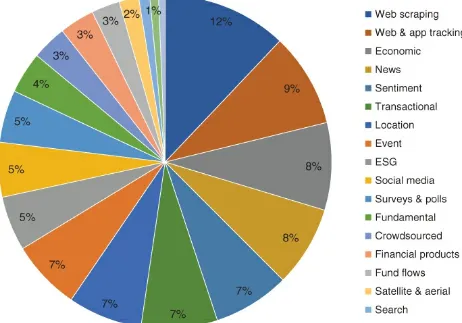
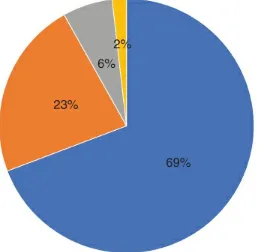
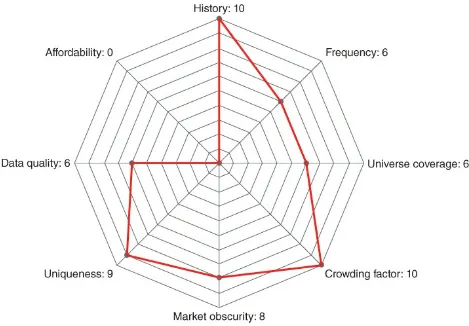
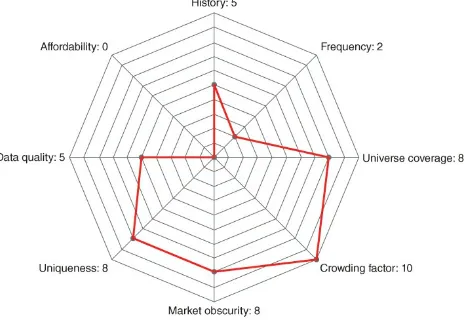
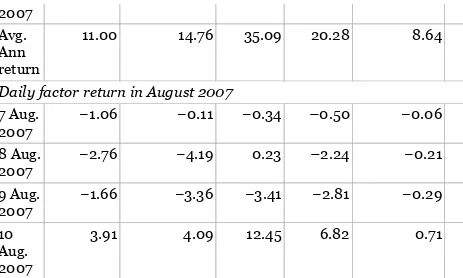
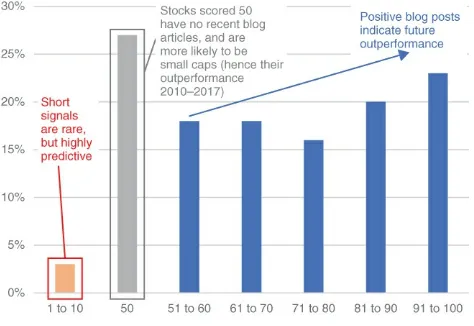
Dokumen terkait
Altogether, twelve configuration settings (three adaptive step size and nine fixed learning rate) were used. For statistical significance, we conducted 30 tests per configuration,
The Execute Python Script module, shown at the bottom of this experiment, runs code for exploring the data, using output from the Execute Python Script module that transforms the
For our first step, we’ll perform some transformations on the raw input data using the code shown below in an Azure ML Execute R Script module:.. ## This file contains the code for
For the first step of this evaluation we’ll create some time series plots to compare the actual bike demand to the demand predicted by the model using the following code:..
This study is limited to supervised and unsupervised machine learning ML techniques, regarded as the bedrock of the IoT smart data analysis.. This study includes reviews and discussions
