Sentiment Analysis Berbasis Big Data Sentiment Analysis Based Big Data
Teks penuh
Gambar

Dokumen terkait
Salah satu wadah untuk mendapatkan informasi yang cepat, tepat dan efisien adalah Internet. Internet sebagai wadah dalam memperoleh suatu informasi inilah yang kemudian
Perlu adanya peningkatan mekanisme data dan informasi yang terintegrasi untuk pengolahan data balita pada bidan praktek mandiri yang dibawah naungan puskesmas sebagai
Untuk dapat menjalankan pelayanan informasi yang cepat, tepat dan sederhana setiap Badan Publik perlu menunjuk Pejabat Pengelola Informasi dan Dokumentasi
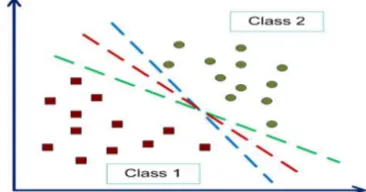
Oleh karena itu, perlu adanya ekstraksi fitur dan klasifikasi wajah menggunakan metode tertentu sehingga klasifikasi tersebut dapat dikenali dengan benar.Pada
Perpustakaan merupakan salah satu unit pelaksana teknis di perguruan tinggi dengan tugas pokoknya sebagai pengelola informasi ilmiah secara efektif dan efisien untuk
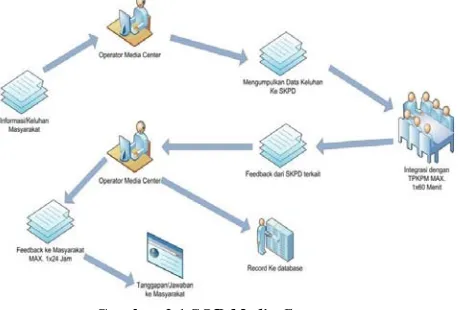
bahwa dalam rangka pelayanan informasi publik yang cepat, tepat, sederhana dan harmonis dan terintegrasi dipandang perlu untuk membentuk 8truktur Organisasi
Untuk dapat menjalankan pelayanan informasi yang cepat, tepat dan sederhana setiap Badan Publik perlu menunjuk Pejabat Pengelola Informasi dan Dokumentasi
Untuk dapat menjalankan pelayanan informasi yang cepat, tepat dan sederhana setiap Badan Publik perlu menunjuk Pejabat Pengelola Informasi dan Dokumentasi
