Pengelompokan Penyakit Hepatitis dengan Menggunakan Metode Fuzzy C-Means ( Studi Kasus Data Penyakit hepatitis di Rumah Sakit Panti Rapih Yogyakarta ) SKRIPSI Ditujukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Jurusan Teknik Info
Teks penuh
Gambar

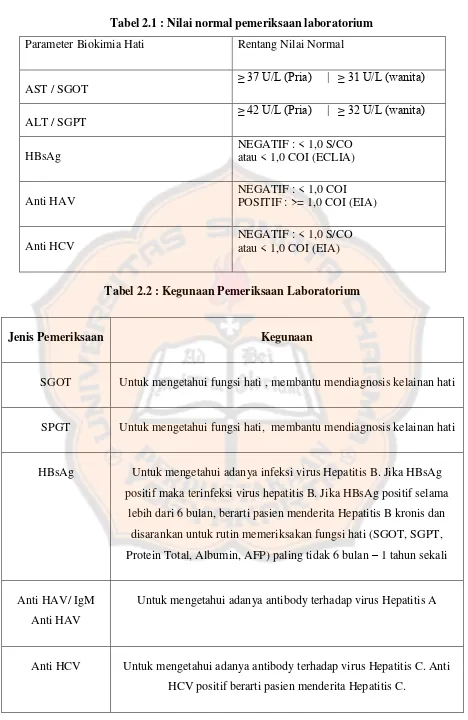
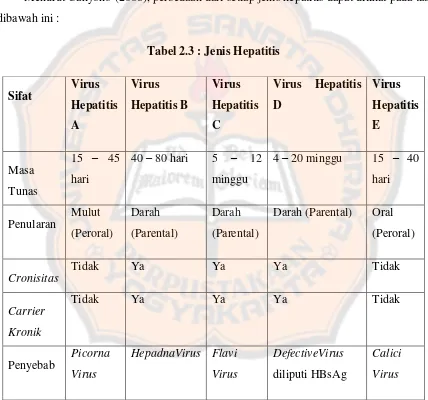
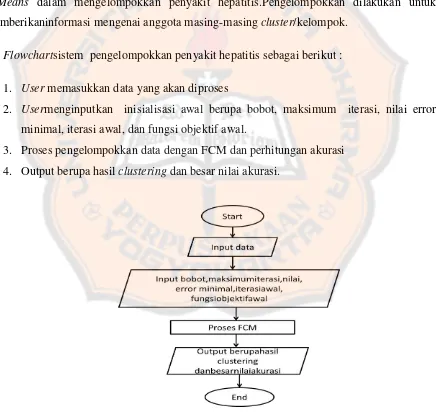
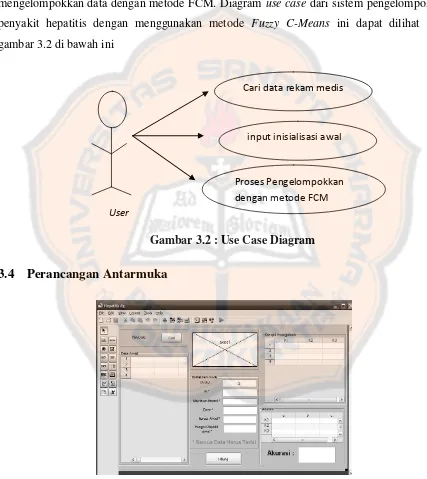

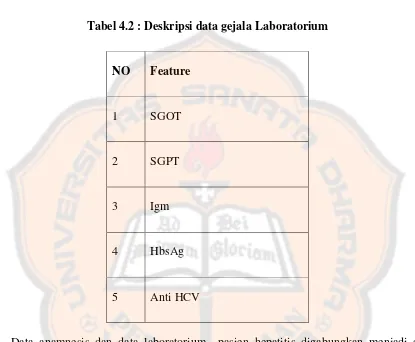
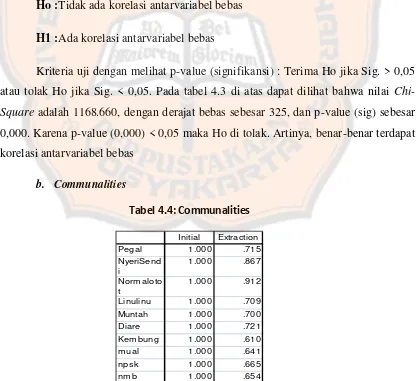
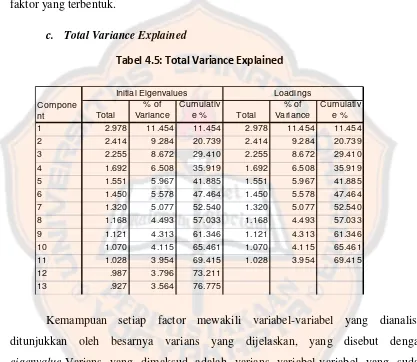
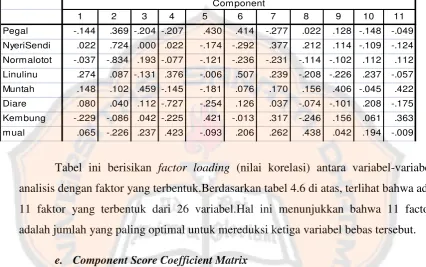
Garis besar
Dokumen terkait
Metode penelitian yaitu menggunakan metode penelitian kualitatif Yaitu: Penelitian yang bermaksud untuk memahami fenomena tentang apa yang di alami atau yang
Pada residu umur 14 hari tampak aktivitas residu insektisida alami dan sintetik turun mencolok, sedangkan aktivitas residu kedua perlakuan formulasi ekstrak
Penahanan di tempat asal dalam ayat ini merupakan penahanan di tempat pengumpulan, pengolahan, dan atau pengawetan antara lain seperti di rumah potong hewan pada waktu
Tanpa menempatkan manusia dan takdirnya di bawah kesewenang-wenangan Tuhan tak dikenal dan membuat mereka takluk terhadap kekuatan tertinggi, agama ini meningkatkan kedudukan
Berdasarkan hasil uji Mann Whitney diperoleh skor eritema yang diberikan perlakuan kontrol negatif dengan kadar 10%, kontrol negatif dengan kadar 20%, kadar 5%
Dengan melihat penataan massa bangunan dan tata ruang tradisional yang tidak memungkinkan untuk dirubah seperti kandang dalam satu atap dan berdekatan dengan
Berapa dari telur itu yang menetas menghasilkan Ayam Pial Single (Bilah) ? A. 2 B. 4 C. 6 D. 8
Başlan gıçta samadhi sırf oluştan veya varoluştan ibaretmiş gibi gelebilir, fakat samadhi’ye eriştiğinizde siz de onun çok daha farklı olduğunu
