PENGELOMPOKAN KABUPATENKOTA DI JAWA TIMUR BERDASARKAN INDIKATOR PEMBANGUNAN EKONOMI MENGGUNAKAN MODEL-BASED CLUSTERING
Teks penuh
Gambar




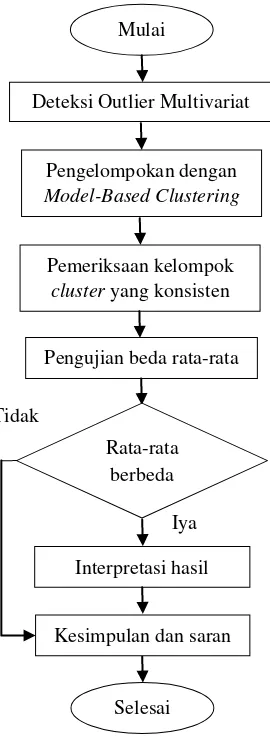
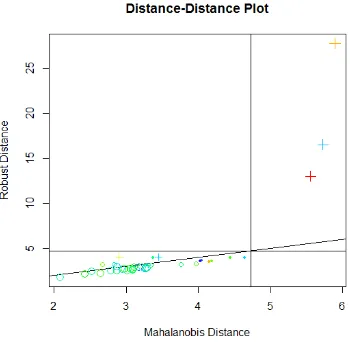
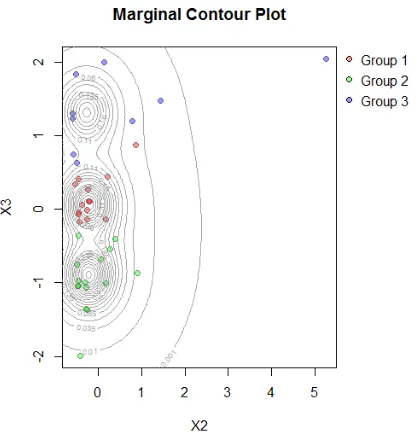
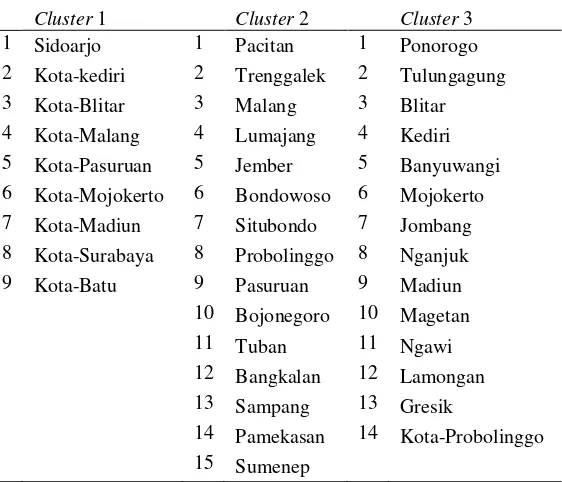
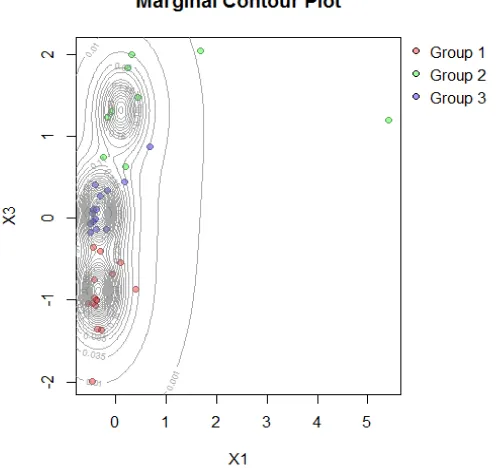
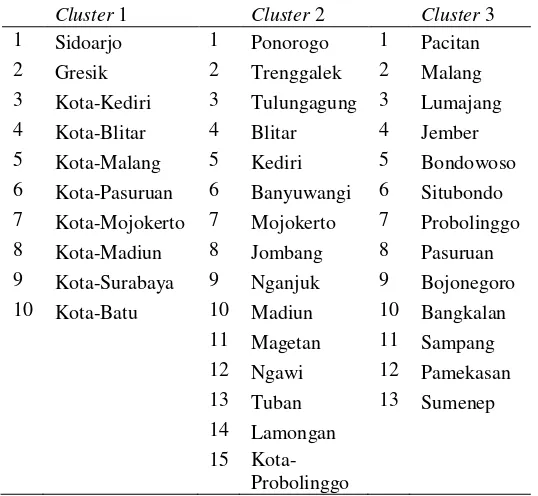
Dokumen terkait
Dalam penelitian ini, penulis menggunakan 9 aspek dari manajemen sumber daya manusia yaitu (1) Tujuan, visi, visi, peraturan perusahaan (2) Perencanaan sumber daya manusia
Penelitian ini bertujuan untuk mendeskripsikan penggambaran maskulinitas laki- laki melalui tokoh Arthur Curry pada film Aquaman karya James Wan. Penelitian ini mengungkap
• Jarak intra atom gugus-gugus yang berinteraksi dengan reseptor pada obat harus sesuai dengan jarak intra atom gugus-gugus fungsional reseptor yang berinteraksi dengan obat..
Di harapkan agar rumah sakit dapat lebih meningkatkan mutu pelayanan dalam memberikan asuhan kebidanan khususnya pada kasus ibu bersalin dengan preeklamsi berat yaitu
Berdasarkan hasil penelitian, dapat di- simpulkan bahwa spesies berudu Anura yang ditemukan di TWAT Kembang Soka pada musim kemarau adalah berudu Leptobrachium hasseltii,
Perancangan Sistem Informasi Kependudukan Usia Produktif dan Angka Kelahiran Pada Desa Grogol sudah diupload ke dalam web dengan URL:
Berdasarkan hasil penelitian yang telah dilakukan, dapat disimpulkan bahwa perbedaan konsentrasi garam berpengaruh terhadap komposisi proksimat ikan biang asin kering.
Sesuai dengan pernyataan tersebut, data penelitian ini menunjukan bahwa seluruh daging di pasar tradisional Bandar Lampung memiliki kualitas baik, karena susut
