Design of Image Processing Embedded Systems Using Multidimensional Data Flow
Teks penuh
Gambar

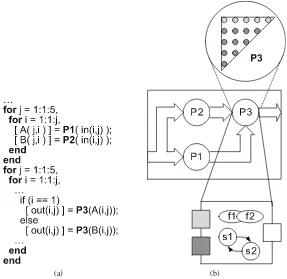
![Fig. 3.8 Reuse chain [89]: (a) Sample code and (b) Reuse chains for sample code](https://thumb-ap.123doks.com/thumbv2/123dok/3943971.1887391/66.439.92.348.214.576/fig-reuse-chain-sample-code-reuse-chains-sample.webp)
![Fig. 3.9 PICO target architecture [162]](https://thumb-ap.123doks.com/thumbv2/123dok/3943971.1887391/69.439.55.384.360.571/fig-pico-target-architecture.webp)
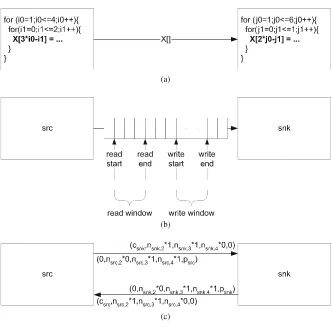
![Fig. 3.18 Communication synthesis in Gaspard2 [36]. a Parallel execution of repetitive tasks](https://thumb-ap.123doks.com/thumbv2/123dok/3943971.1887391/93.439.63.378.53.341/fig-communication-synthesis-gaspard-parallel-execution-repetitive-tasks.webp)
Dokumen terkait
ANALISIS KETERSEDIAAN SISTEM INFORMASI PRAKERIN PADA WEBSITE SEKOLAH MENENGAH KEJURUAN (SMK) DI JAWA BARAT.. Universitas Pendidikan Indonesia | repository.upi.edu
Pelayanan keperawatan adalah bagian dari sistem pelayanan kesehatan di Rumah Sakit yang mempunyai fungsi menjaga mutu pelayanan, yang sering dijadikan barometer
Apabila Saudara membutuhkan keterangan dan penjelasan lebih lanjut, dapat menghubungi kami sesuai alamat tersebut di atas sampai dengan batas akhir pemasukan Dokumen
12) Khusus untuk barang milik Pusat dalam hal ini Departemen Lain kalau sudah ada aturan/petunjuk dari Departemen yang bersangkutan, maka pengguna/kuasa pengguna
perubahan yang terjadi pada wilayah pemukiman sekitar Kecamatan Purwantoro,. yang selanjutnya akan digunakan sebagai langkah awal merumuskan
Tôi rất hân hạnh đem đến với bạn đọc Bản tin đầu tiên của Chương trình Công bằng cho người dân và tăng cường mạng lưới ở khu vực Mekong (GREEN Mekong) được đặt
Mendes-kripsikan interaksi sebagai proses sosial Buku bse IPS, Waluyo, dkk dan buku IPS Mandiri SMP Kelas 7 Buku Sumber: No.. Proses imitasi seseorang pertama kali
Alhamdulillah, segala puji syukur hanya kepada Allah SWT yang selalu memberikan petunjuk dan kekuatan sehingga penulis dapat menyelesaikan skripsi dengan judul “AKTIVITAS
