Real Time Big Data Analytics Emerging Architecture pdf pdf
Teks penuh
Gambar
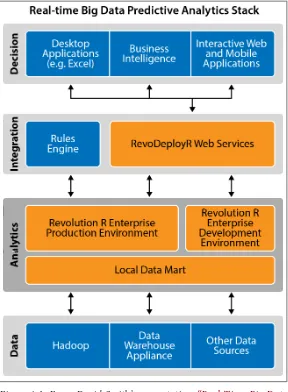

Dokumen terkait
Calon Penyedia diharapkan membawa berkas-berkas asli sesuai dengan dokumen yang di- upload, Cap Stempel Perusahaan dan salinan dokumen penawaran sebagai dokumen pokja. Calon
4 Penutup Mengajak mahasiswa untuk mengulangi pembahasan seluruh materi yang telah didiskusikan selama kegiatan tutorial III tentang pengelolaan sumber daya penerbitan dan
3. Penelitian gandum ke depan diharapkan dapat menghasilkan varietas yang adaptif pada dataran menengah dan rendah dengan potensi hasil tinggi sehingga mampu bersaing dengan
Since there is no variety field in the database with the specified value (which is exactly what the malicious user entered: lagrein' or 1=1; ), this query will return no results,
HASIL DAN PEMBAHASAN Hasil pengamatan terhadap pertumbuhan bibit lada (tinggi tanaman, jumlah buku, jumlah daun dan berat kering akar), menunjukkan bahwa tidak
Penelitian ini dilakukan dengan tujuan untuk mengetahui Sikap Masyarakat di Surabaya dalam menonton tayangan acara Reality Show Uya Emang Kuya di SCTV.. Dengan menggunakan
Kemudian program kompensasi juga penting bagi perusahaan, karena hal itu mencerminkan upaya organisasi untuk mempertahankan sumberdaya manusia atau dengan kata lain agar
Pada hari ini Kamis tanggal Dua Puluh Dua bulan Mei tahun Dua Ribu Empat Belas kami yang bertanda tangan dibawah ini Kepala Unit Layanan Pengadaan (ULP)
