stratasurvey Ebook free download pdf pdf
Teks penuh
Gambar


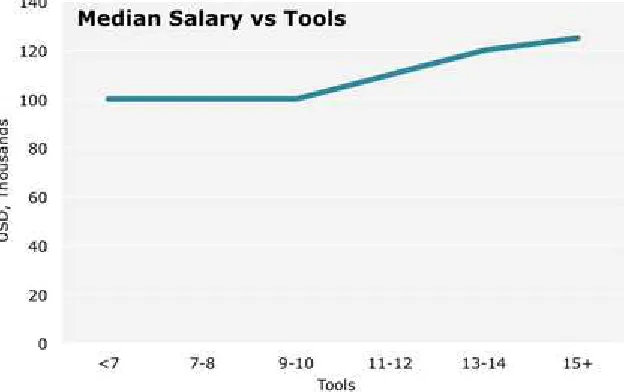
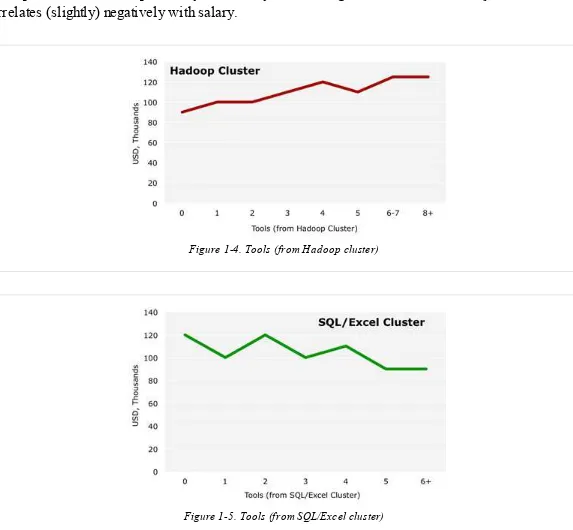
Dokumen terkait
The data itself is opaque to the optimizer, which means Spark gets an object either in Scala, Java, or Python and the only thing Spark as a Framework can do is to take a Serializer
It will cover real-time use case scenarios to explain integration and achieving Big Data solutions using different technologies such as Apache Hadoop, Apache Sqoop, and MySQL
The Flume project is designed to make the data gathering process easy and scalable, by running agents on the source machines that pass the data updates to collectors, which
Tools discussed in this chapter include graphical editors that emphasize visual components instead of code, code editors that provide hints and immediate feedback, code libraries
Not only that, but it also requires the source code to be compiled to platform- specific machine code at build time - usually called Ahead of Time (AOT) compilation.. This is
This includes data visualization tools and time series databases as well as stream processing systems and glue
In modern Python, all classes need to inherit from a built-in base class called object. class DogFromObject
If you’re using the Tools palette Blend tool, you select the tool, click the first object, and then click the second object... Be careful: Where you click the objects can
