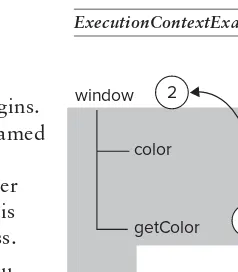
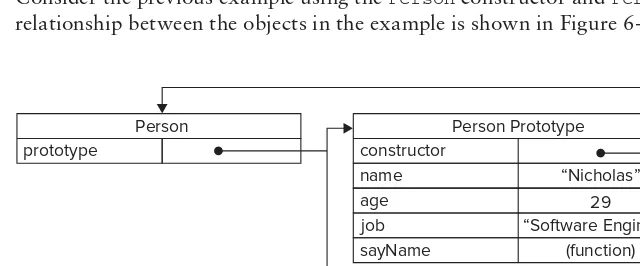
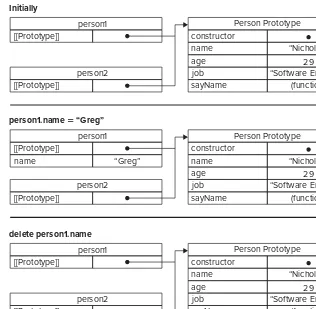
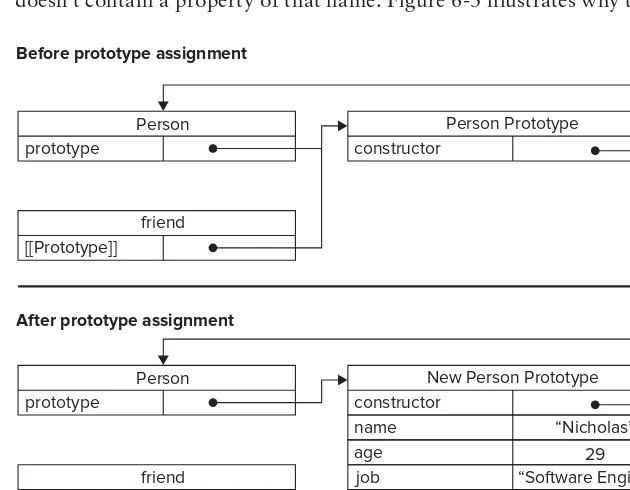
483 Professional JavaScript for Web Developers, 3rd Edition
Teks penuh
Gambar


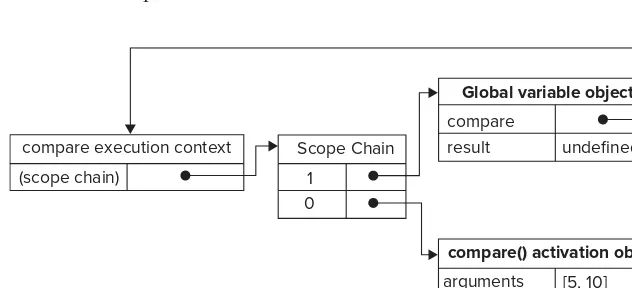
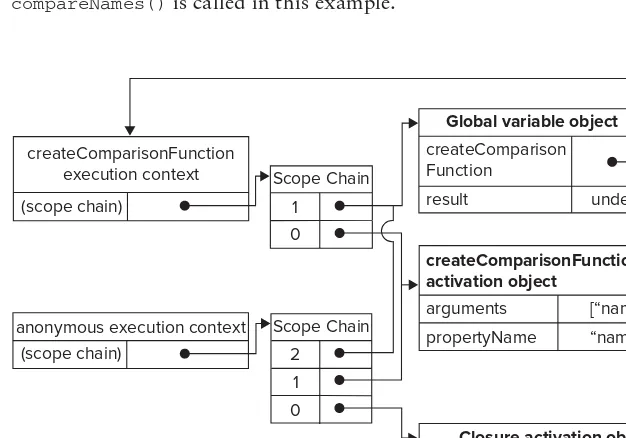

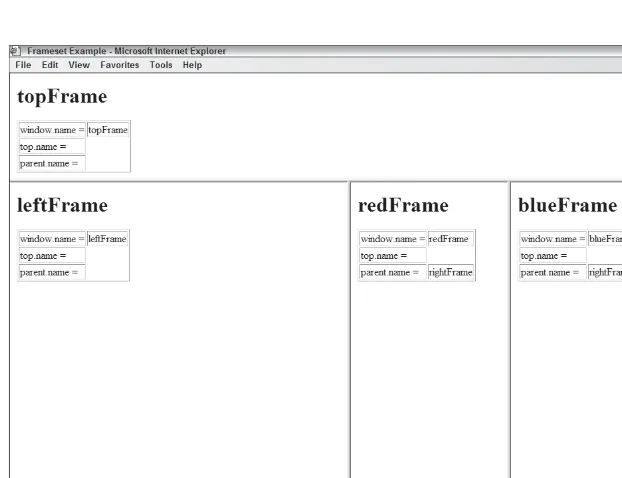
Dokumen terkait
Tenaga kerja tidak langsung adalah pekerja yang bekerja di luar
It combines a range of process such as: Mobile Commerce, Electronic Fund Transfer, Supply Chain Management, Internet Banking, Online Transaction Processing,
Namun, tidak semua individu memiliki percaya diri yang cukup, seperti yang ditemukan dalam keseharian peserta didik kelas XII PS 1 SMK Raden Umar Said Kudus,
dapat meningkatkan hasil belajar Matematika pada siswa kelas 4 SDN Jambu. 01 Kecamatan
Sehubungan dengan itu, tujuan analisis ini adalah untuk mengestimasi dampak kebijakan proteksi (tarif dan nontarif) yang dilakukan pemerintah Indonesia
mengandung sel-sel dari strain-strain efektif mikroba penambat nitrogen, pelarut fosfat atau selulolitik yang digunakan pada biji, tanah atau tempat pengomposan
Hasil uji SEM sampel tanah dengan Bakteri Pseudomonas sp pada masa pemeraman 30 hari Gambar (a) adalah sampel tanah pasir yang menggunakan pengaruh bakteri pseudomonas
Hasil yang diperoleh menunjukkan bahwa harga dan kualitas pelayanan mempengaruhi kepuasan pelanggan dalam menggunakan jasa air minum Pada PDAM Tirta Nchio Sidikalang.. Diperoleh
