Linux All In One For Dummies 6th Edition pdf pdf
Teks penuh
Gambar



Garis besar
Dokumen terkait
To view the Followers report, click the Followers tab within Facebook Insights (see Figure 10-7), which also shows you the Total Page Followers As of Today. This graph
Choose Ú ➪ System Preferences and click the Universal Access icon in the Personal section to open the Universal Access preferences pane, as shown in Figure 5-12.. Click the
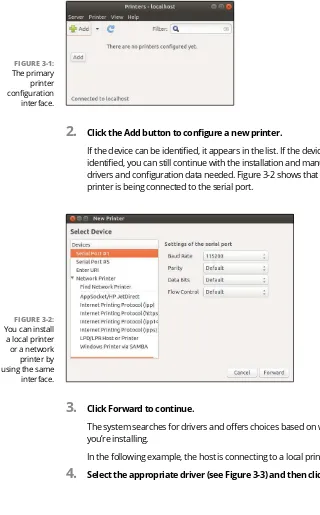
Then use the Page Setup dialog box to set options specific for that printer, such as paper size and paper trays.. » A Print dialog box might share some of the same settings as the
I n addition to choosing a size and resolution (discussed in Book II, Chapter 1), you need to decide on a color mode and file format for your image.. Usually, you base this
If you really want to drive your techie friends nuts, the next time you have a problem with your computer, tell them that the hassles occur when you’re “running Microsoft.” They
Just connect the iPad to your computer (either by Wi-Fi Sync or USB cable, as page 12 describes), click the iPad icon in the iTunes window, and then click the Info tab at the top
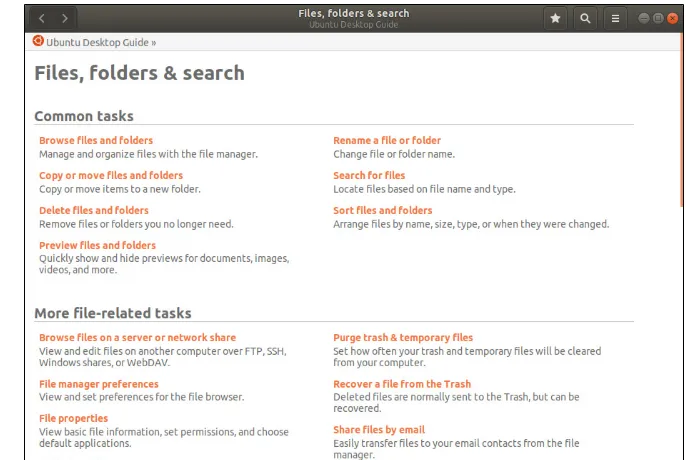
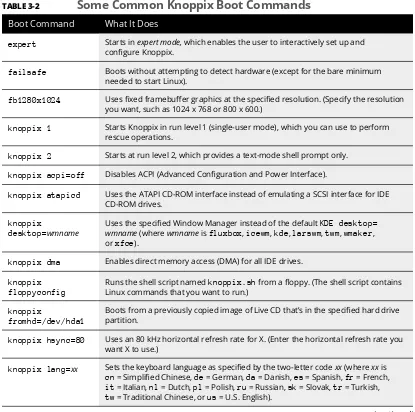
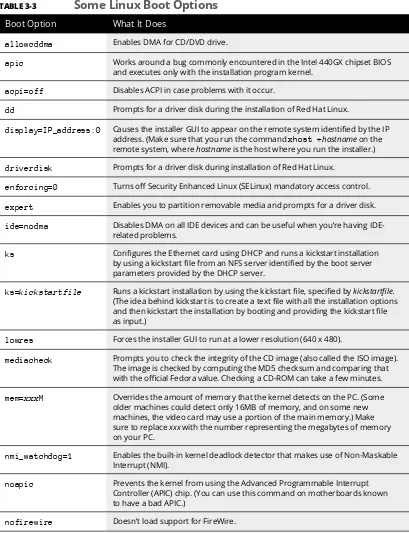
⻬ Part II: Test-Driving SUSE is about getting started with SUSE Linux — how to use the desktop and the file manager, how to connect to the Internet (and set up a home network) —
Laptop users can gain access to the Internet in several ways: by using a dial-up modem in connection to the plain old telephone system (POTS); by WiFi inter- change with a
