Linux Network Servers pdf pdf
Teks penuh
Gambar
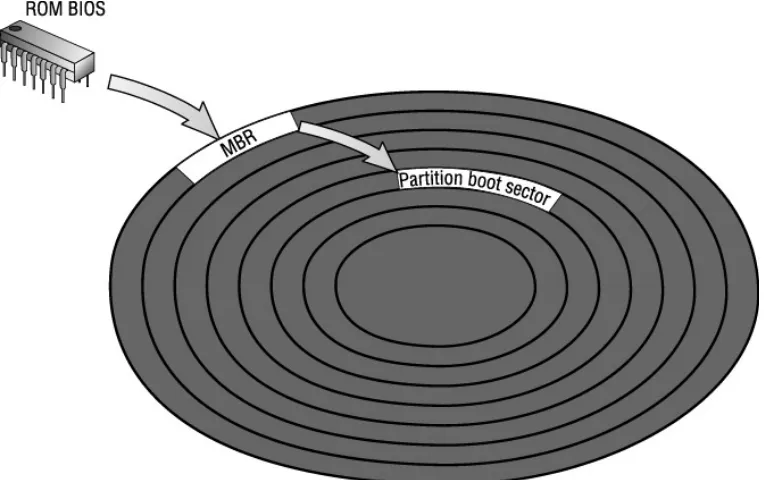

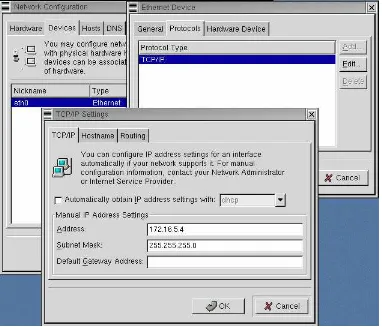
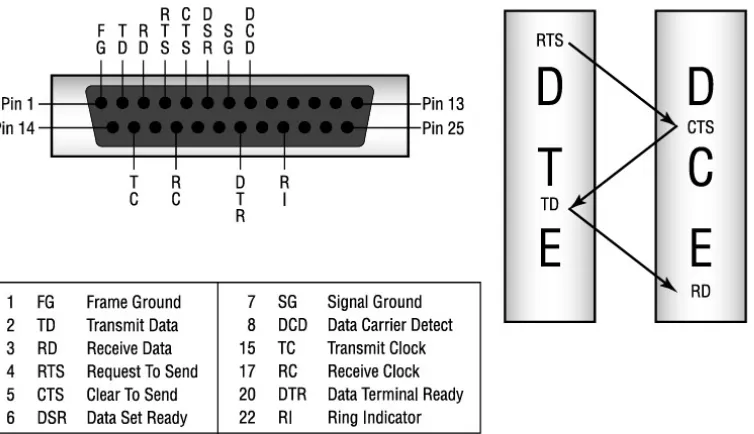



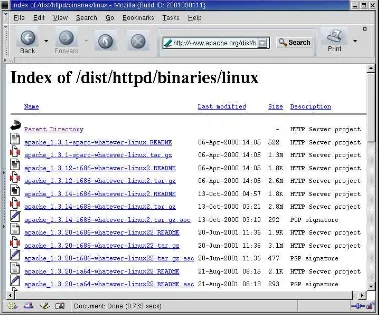
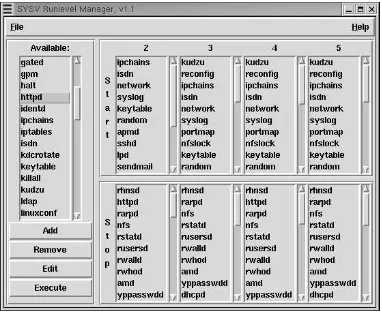

Garis besar
Dokumen terkait
[r]
The National Research Council report, Valuing Ecosystem Services: Toward Better Environmental Decision-Making , identifies methods for assigning economic value to
Citation: Selkani I (2016) The Attractiveness of the Territory via the Place Marketing Case of the International Festival of Nomads: M'hamid El Ghizlane– Zagora-Morocco.. This is
Pada bab III akan dijelaskan mengenai metode penelitian yang akan digunakan oleh peneliti dalam mengkaji skripsi yang berjudul “Peran Thailand dalam South East
Pada hari ini Jumat tanggal Tujuh belas bulan Juni tahun Dua ribu enam belas bertempat diruang sekretariat Unit Layanan Pengadaan Kordinator Pengadilan Tinggi Kendari, telah
Dengan kata lain, penyelenggaraan program KKO berlandaskan pada “olahraga prestasi”, yaitu pembinaan dan pengembangan olahraga yang dilakukan untuk diarahkan
Berdasarkan Berita Acara Hasil Pelelangan No : 23/POKJA -ULP II/FSK/PSBK/5/2015 tanggal 27 Mei 2015 bahwa pemilihan Penyedia Barang dan Jasa Paket Pekerjaan
Berdasarkan penelitian pada toko Mitra, toko ini masih dilakukan secara manual sehingga resiko kesalahan pada proses perhitungan barang dan membutuhkan waktu yang lama,
