Practical Mod Free ebook download Free ebook download
Teks penuh
Gambar
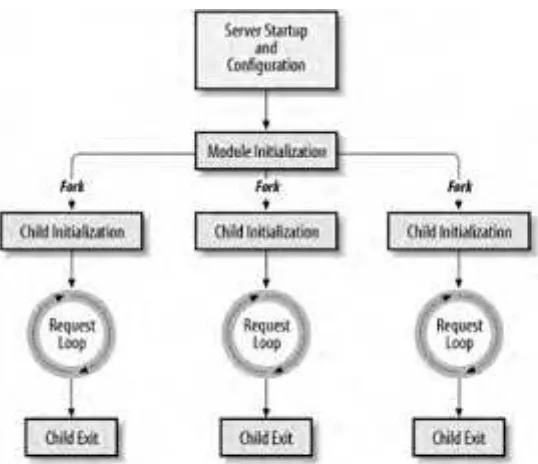
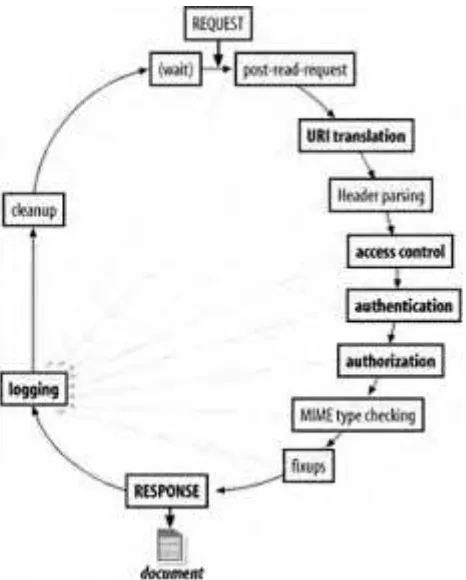
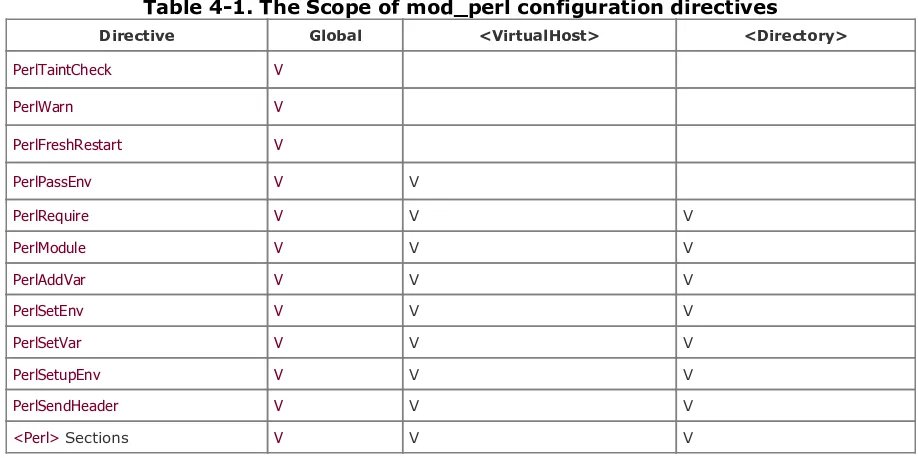
Dokumen terkait
Trichophyton sp merupakan jamur yang dapat menyebabkan penyakit kulit pada manusia seperti panu, kadas dan kurap, dengan gambaran kilns berupa permukaan
Sikap jujur dibiasakan dengan cara guru harus berkerja sama dengan orang tua untuk memantau siswa, misalnya jika di sekolah maka tugas guru untuk memantau siswa bersikap jujur
Gerakan 1 Rumah 1 Jumantik merupakan pemberdayaan masyarakat dengan melibatkan setiap keluarga untuk melaksanakan pemeriksaan, pemantauan dan pemberantasan jentik nyamuk
Faktor yang Berhubungan dengan Keberadaan Jentik Aedes aegypti di Daerah Endemis Demam Berdarah Dengue ( DBD ) Jakarta Barat Factors Related to The Existence of Aedes
Adapun judul yang akan diambil adalah “Peran Strategi Promosi dalam Upaya Meningkatkan Penjualan Produk Jasa AsuransiPada PT Asuransi Bringin Sejahtera Artamakmur
Terdapat penghambatan angiogenesis pada membran korioalantois telur ayam berembrio setelah pemberian ekstrak etanol biji jintan hitam (Nigella sativa) dosis 75 µg, 90
Background dari halaman ini adalah permainan pada siang hari dengan tema yang dapat berubah dan terdapat kotak garis sebagai arena permainan seperti yang
Tinjauan tentang Antibiotik Infeksi Saluran Kemih Menurut Standar Diagnosa Dan Terapi Rumkital Dr.Ramelan Surabaya .... Tinjauan tentang Antibiotik Menurut
