Advances in Communication Networking 20th EUNICE IFIP EG 6 2, 6 6 International Workshop pdf pdf
Teks penuh
Gambar
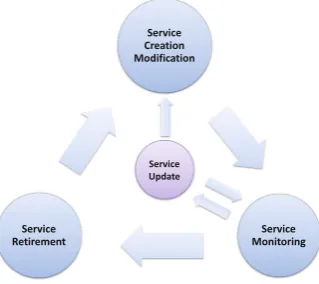
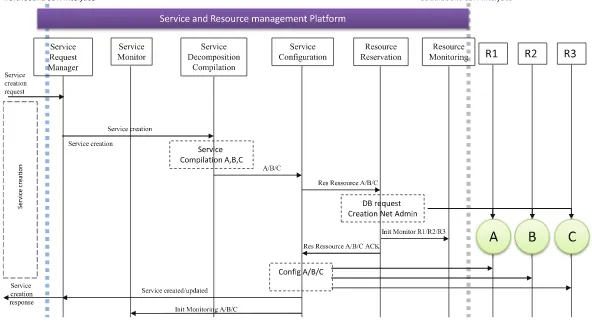
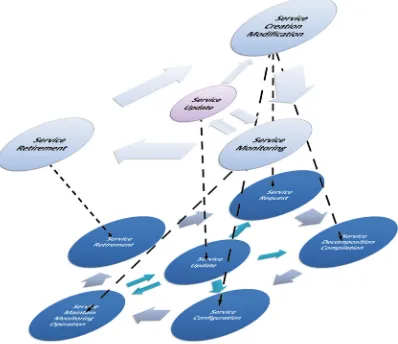
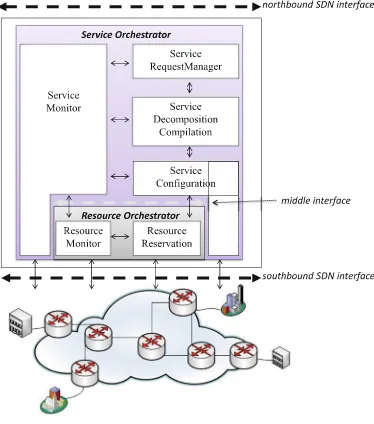
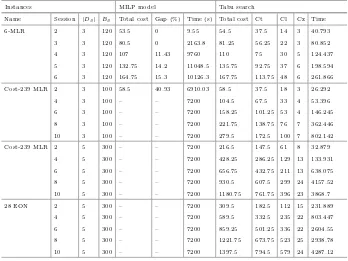
![Fig. 1. Evolution of costs versus the number of iteration of the tabu search on the6-node transparent MLR topology [9]](https://thumb-ap.123doks.com/thumbv2/123dok/3934912.1878332/32.439.91.335.309.566/evolution-costs-versus-number-iteration-search-transparent-topology.webp)
Dokumen terkait
BAB II PEMBELAJARAN MENULIS PUISI DALAM MODEL SINEKTIK BERBASIS TERJEMAH AYAT ALQURAN
Hasil penelitian menunjukkan bahwa sebagian besar mahasiswa berpendapat tidak setuju dengan istilah Islam Nusantara yang berpotensi menimbulkan perpecahan
Berdasarkan hasil penelitian, perlakuan terbaik adalah perlakuan lama fermentasi 24 jam: konsentrasi starter 5 % yang menghasilkan minuman sinbiotik ubi jalar ungu dengan
Rata-rata Kadar Klorofil a, Klorofil b dan Klorofil total Tanaman Wheatgrass pada Perlakuan Kombinasi antara Media Tanam dan Volume Penyiraman yang Berbeda ………. Rata-rata
Setelah masalah ditemukan/dipilih dan kemudian dianalisis kemungkinan penyebab dan alternatif pemecahannya, maka tugas guru peserta selanjutnya adalah menyusun
Dampak Pelatihan Stabilisasi Dan Fleksibilitas Panggul Terhadap Penampilan Poomsae (Taegeuk Ohjang) Pada Cabang Olahraga Taekwondo.. Universitas Pendidikan Indonesia |
error rate (CER) (typically used in handwriting recognition as well as in discrete text input.. as is done at a keyboard)
Dengan demikian maka pendidikan akan menjadi pewaris budaya, dan sekaligus berfungsi untuk mengembangkan kehidupan sosial maupun budaya kearah yang lebih baik
