kubernetes Ebook free download pdf pdf
Teks penuh
Gambar

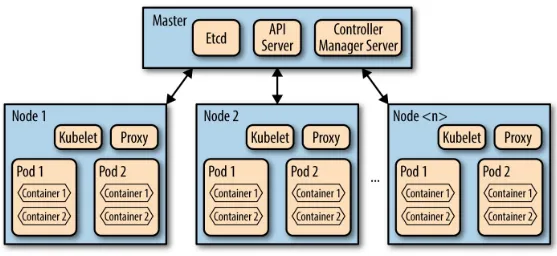
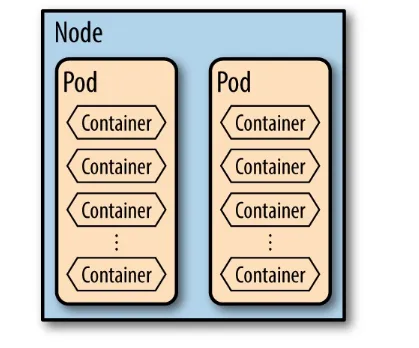
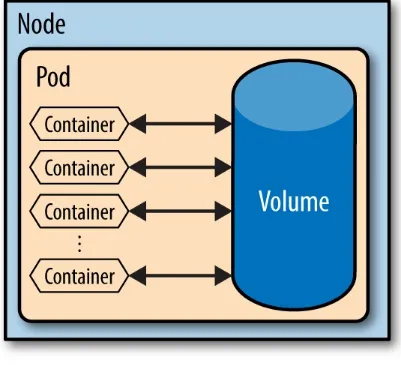
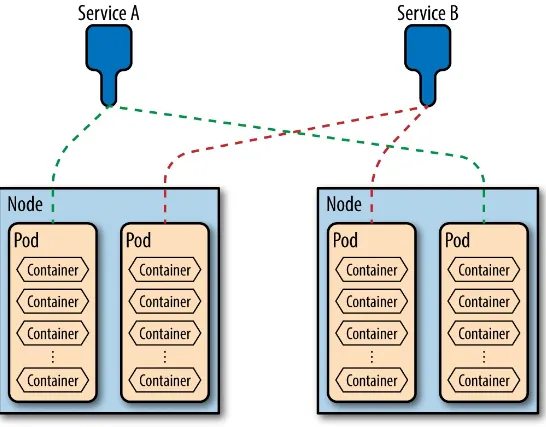
Garis besar
Dokumen terkait
This marked increased in the number of renal allograft biopsies reported in recent years may be largely contributed by the marked increased in the number of
In the native kidney biopsy group, the three most common primary glomerulonephritis (GN) reported were focal segmental glomerulosclerosis (FSGS) (36%), minimal change disease
National Mental Health Registry (NMHR) would be addressing the first component of health information which is current services and clients; input regarding criteria for access
Dari contoh-contoh ijtihad yang dilakukan oleh Rasulullah SAW, demikian pula oleh para sahabatnya baik di kala Rasulullah SAW masih hidup atau setelah beliau
Batang Tubuh (body of constitution) Undang-Undang Dasar 1945 terdiri dari rangkaian pasal-pasal yang merupakan uraian terinci atau perwujudan dari pokok- pokok pikiran yang
Sequence reference of Trypanosoma on ESAG6/7 site from gene bank for amino acid analysis
[r]
Hasil penelitian menunjukkan proporsi infeksi cacing yang ditularkan melalui tanah masih tinggi pada kelompok usia sekolah dasar di SD Negeri Abe Pantai Jayapura 50%
