Addison Wesley C Plus Plus Standard Library The A Tutorial And Reference Aug 1999 ISBN 0201824701
Teks penuh
Gambar
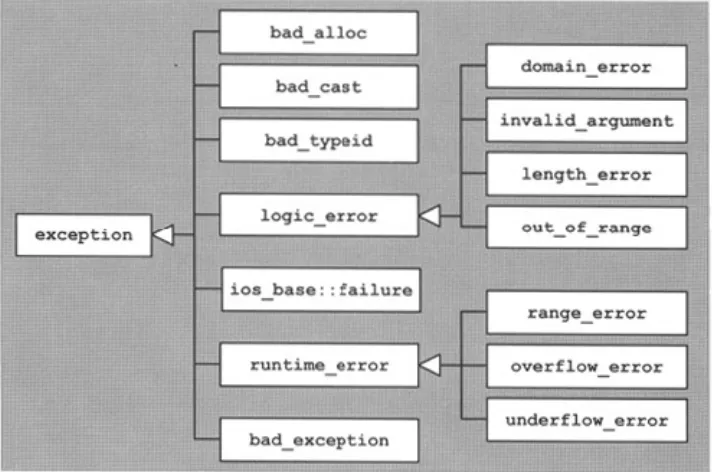

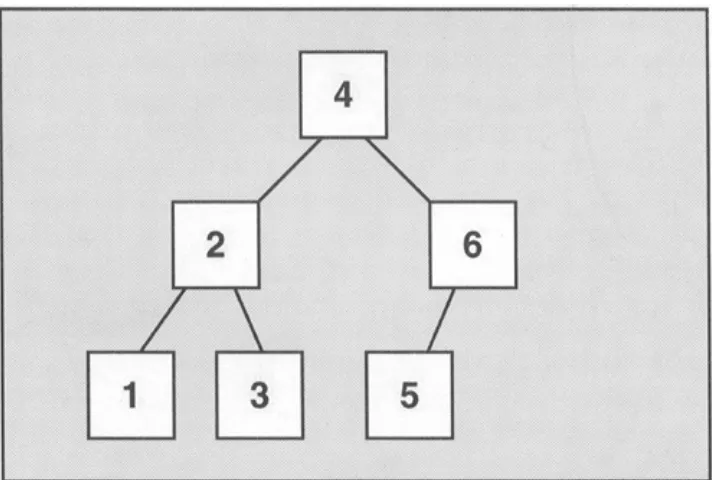



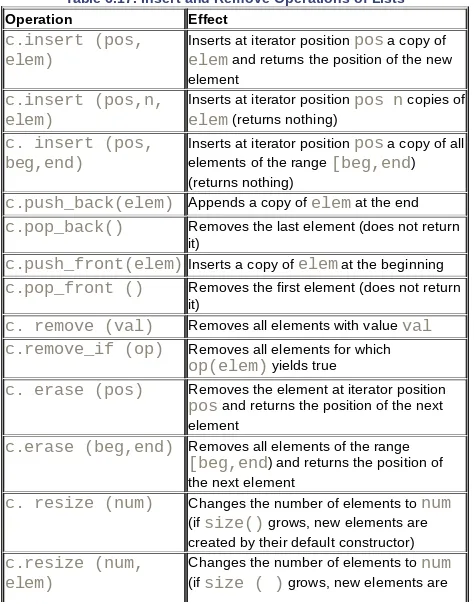

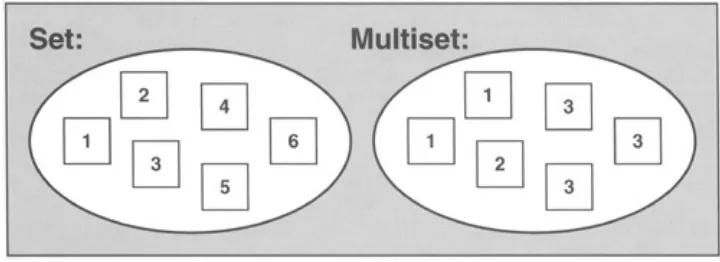
Dokumen terkait
Pertemuan Ilmiah Tahunan (PIT) X Departemen Ilmu Penyakit Dalam Fakultas Kedokteran Universitas Sumatera Utara Medan. Pembicara pada The Malacca Strait
Figure 2A: Uptake of I-125 labeled anti–Aß antibodies in the cerebral cortex at different time - points after intranasal (IN) or intraperitoneal (IP) delivery in mice expressed
tunjangan kinerja sesuai dengan aturan yang berlaku kepada para. pegawainya dan melakukan evaluasi berkelanjutan demi
(BORANG HENDAKLAH DIISI OLEH GURU MATA PELAJARAN PENDIDIKAN JASMANI). NAMA
Sebaliknya, sejalan dengan Scott (1985), menurut penulis, selain oleh keterbatasan- keterbatasan ekonomi, kegagalan dominasi kolonialisme, aristokrat tradisional, pemerintah
“In a technical sense, the Internet is intrinsically convergent,” says Chris Greer, director of the Smart Grid and Cyber-Physical Systems Program Office, and national coordinator
[r]
Perlunya penelitian di bidang jaringan syaraf tiruan dengan menggunakan metode lainnya untuk proses klasifikasi, kemudian dilakukan perbandingan sehingga dapat
