Klasifikasi Multilabel Motif Citra Batik Menggunakan Boosted Random Ferns Dengan Ekstraksi Fitur Histogram of Oriented Gradient - ITS Repository
Teks penuh
Gambar



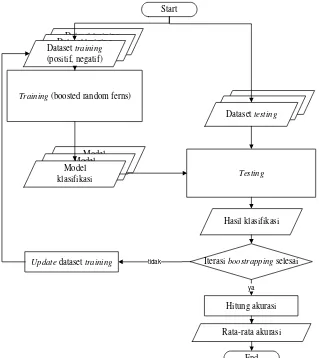
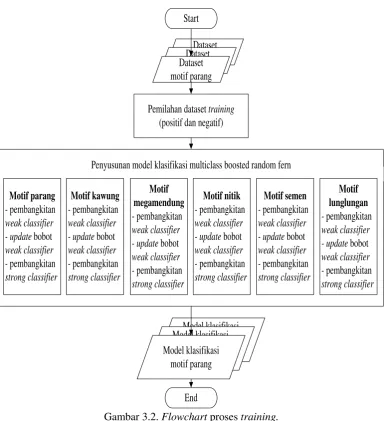
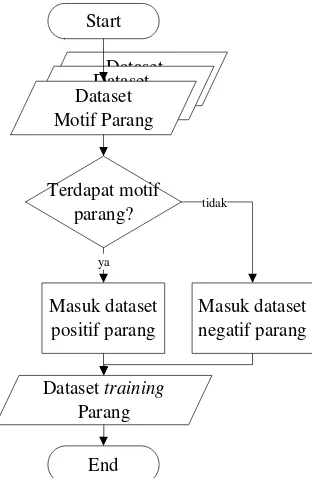
Dokumen terkait
Rata-rata tren pertumbuhan nilai jual produk furnitur cenderung dimana Pertumbuhan Nilai Ekspor tahun 2010-2012 Perusahaan Furnitur Ekolabel di wilayah
Pihak SMK Negeri 1 Tebing Tinggi belum memiliki suatu sistem atau perangkat yang dapat digunakan untuk menentukan kadar kebersihan air tersebut..
Dengan pengetahuan dan pengalaman yang dimiliki, para pendidik yang ada di sekolah, terutama guru BK, guru Agama, dan guru Budi Pekerti, dapat berperan aktif dalam mencegah
Pembaruan data ketinggian air dilakukan setiap 1 menit ke media sosial twitter melalui Ethernet Shield Gambar diagram blok pengujian mikrokontroler Arduino UNO
Dalam beberapa kasus, menjadi social entrepreneur dalam konteks ini mengabdi sebagai volunteer atau amil lembaga zakat belumlah menjadi pilihan utama sebagian
Hal ini menunjukkan model tidak mengandung heteroskedastisitas dan dapat digunakan untuk menganalisis pengaruh manajemen laba (akrual dan riil) terhadap kinerja
Gambar 1. Kerangka Pemikiran dan Pemecahan Masalah.. yaitu dengan pemilihan bahan baku yang berkualitas. Hal ini sangat didukung oleh tersedianya bahan baku yang mudah
Pada bagian tengah, kedalaman batu gamping dengan kandungan CaO tinggi lebih dalam dari yang diperoleh pada bagian Barat pada lokasi penelitian, tapi tidak sedalam
