Networking for Big Data Chapman pdf pdf
Teks penuh
Gambar
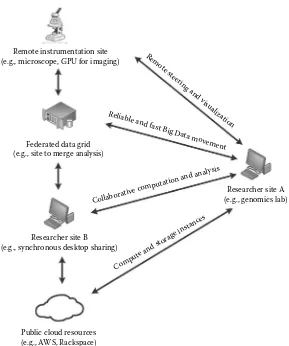
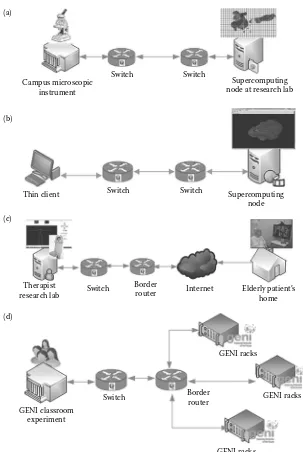
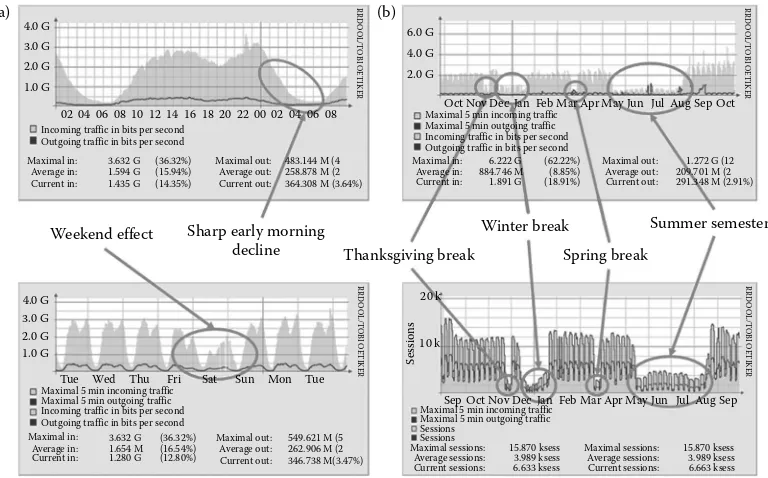
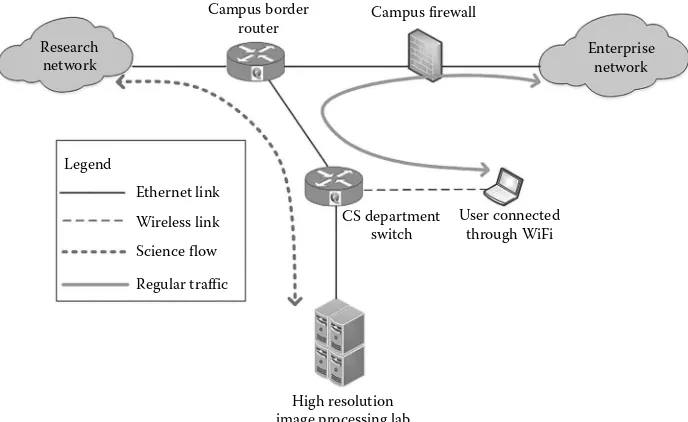
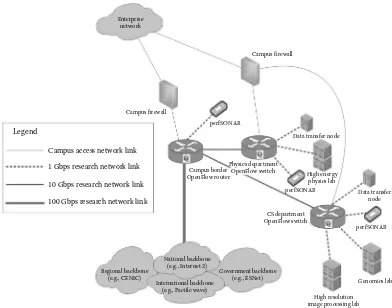
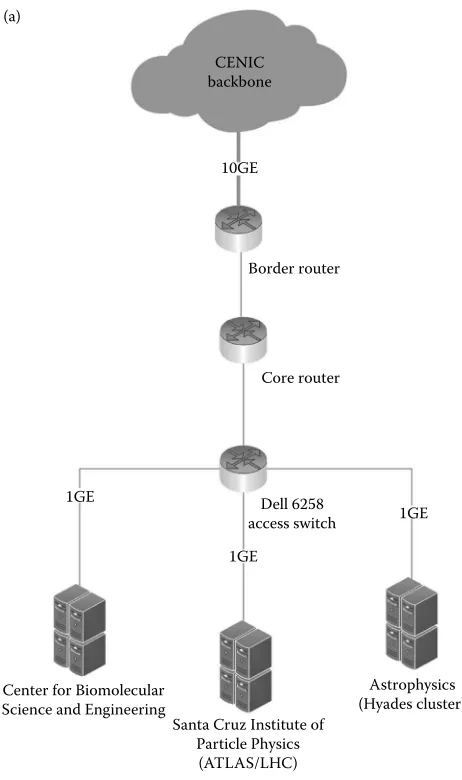
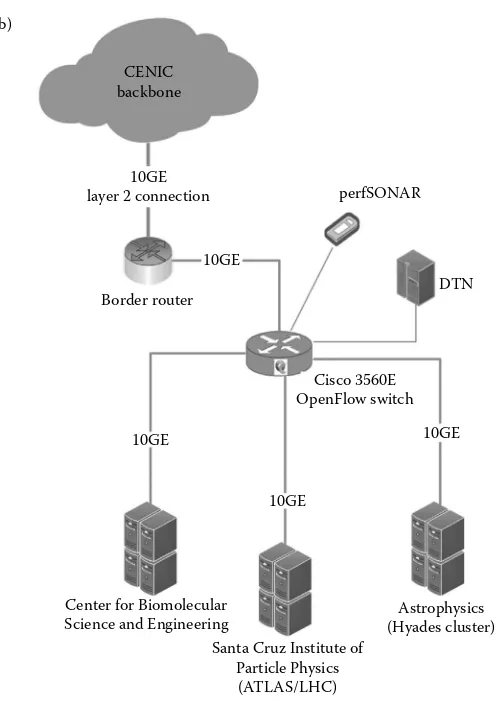
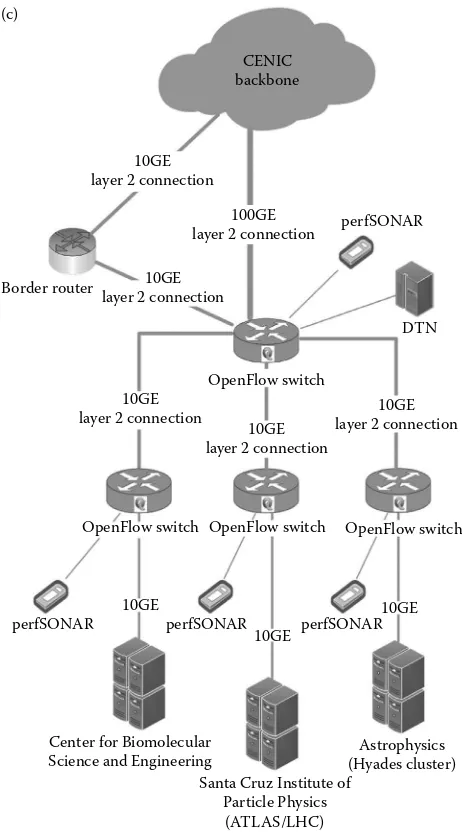
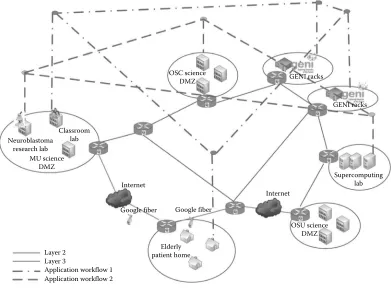
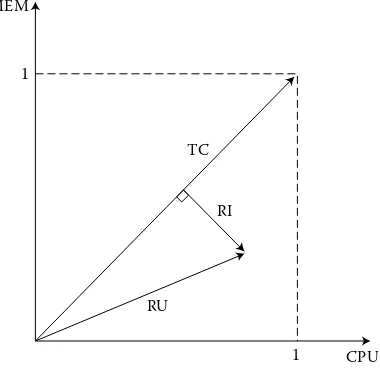
Garis besar
Dokumen terkait
Atas dasar pemikiran di atas, maka perlu diadakan penelitian mengenai Faktor-Faktor Yang Mempengaruhi Pengambilan Keputusan Nasabah Dalam Memilih Produk Bank
The objective of the research in this study is to describe the process of teaching and learning English for children with mental retardation of the fifth
2013.An Analysis of Speech Function In The Transcript Of Face 2 Face Interview Of Desi Anwar With Richard Gere on July 23, 2011.Skripsi.English Education Department,
Laboratorium merupakan suatu kesatuan yang secara legal dapat dipertanggungjawabkan. Kegiatan laboratorium dilakukan dengan sebaik-baiknya sehingga dapat memberikan data
Aplikasi CMA pada tanaman jagung di tanah Inceptisol dapat meningkatkan infeksi akar, serapan fosfat, bobot kering tanaman, dan hasil pipilan kering seiring dengan
Menyatakan dengan sebenarnya bahwa skripsi saya dengan judul : “PERLINDUNGAN HUKUM ANAK ANGKAT BERDASARKAN PERATURAN PEMERINTAH REPUBLIK INDONESIA NOMOR 54 TAHUN 2007
(diameter 2-5 mm) dari tujuh varietas yang dapat menghasilkan umbi mini dengan nisbah perbanyakan berkisar 6,07 (Cipanas) dan 13,22 (Merbabu) ditunjang dengan teknik produksi
Tujuan dari pelaku UMKM membuat pencatatan dan pelaporan keuangan secara akuntansi hanya untuk mengetahui laba/rugi dari usaha yang dilakukan (77.42%), sedangkan
