Designing Reactive Systems pdf pdf
Teks penuh
Gambar
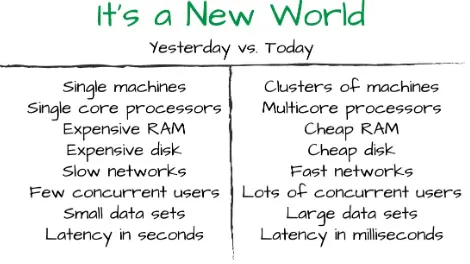
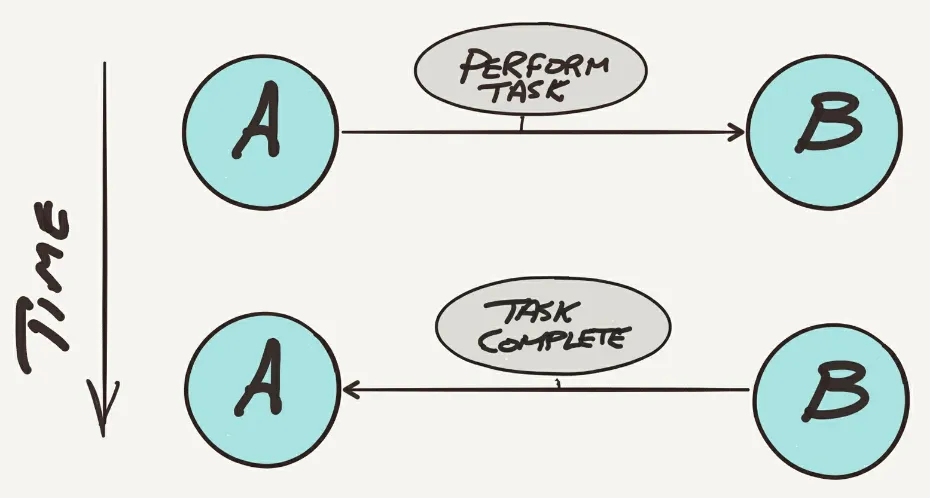
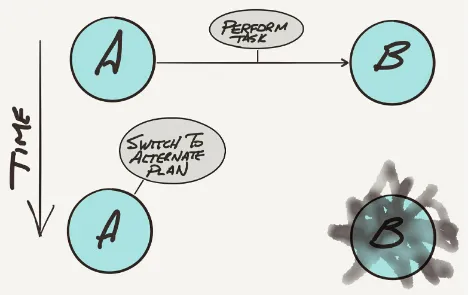
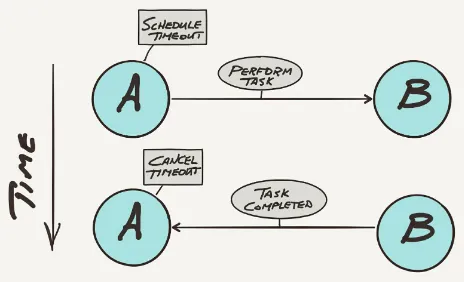
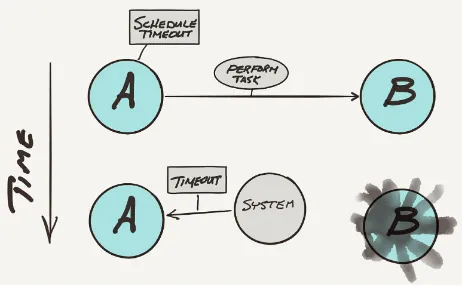
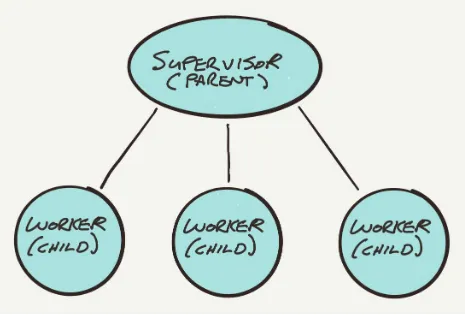
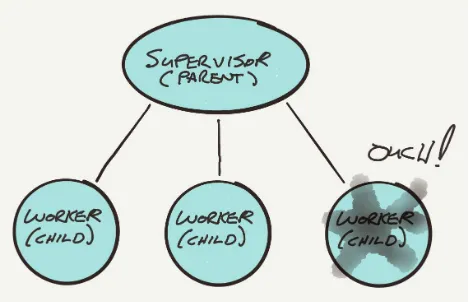
Garis besar
Dokumen terkait
Banyak ilmuwan mulai meneliti untuk mencari jenis energi baru yang murah, mudah dan ramah lingkungan untuk menggantikan sumber energi yang tersedia sekarang, yaitu dengan
Massa Protein dan Kalsium Daging pada Ayam Kedu Awal Bertelur yang diberi Ransum dengan Level Protein Berbeda, penelitian yang terkait dengan karya ilmiah ini
Universitas
Berdasarkan hasil penelitian, bisa disimpulkan bahwa proses sintesis zeolit dengan menggunakan microwave dengan bahan baku abu dari sekam padi bisa dijalankan
Bila yang bersangkutan beragama Islam, namun tak dapat membuktikan terjadinya perkawinan dengan akta nikah, dapat mengajukan permohonan istbat kawin
Tiada kata lain yang diucapkan pada awal kata pengantar ini, selain ucapan puji dan syukur kepada Tuhan Yang Maha Esa atas kasih dan rahmat-Nya, sehingga penulis dapat
masalah keagenan yang lain antara pemegang saham pengendali dengan. pemegang saham
Sesuai dengan jadwal pelelangan sederhana Pekerjaan Fasilitasi Bantuan Kepada Petani Bawang Merah Tahun Anggaran 2015 pada Satuan Kerja Dinas Pertanian Tanaman Pangan dan
