designing reactive systems Ebook free download pdf pdf
Teks penuh
Gambar
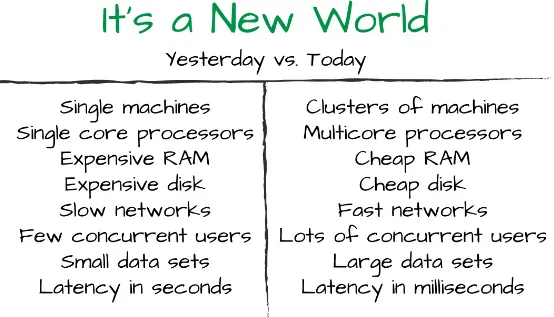
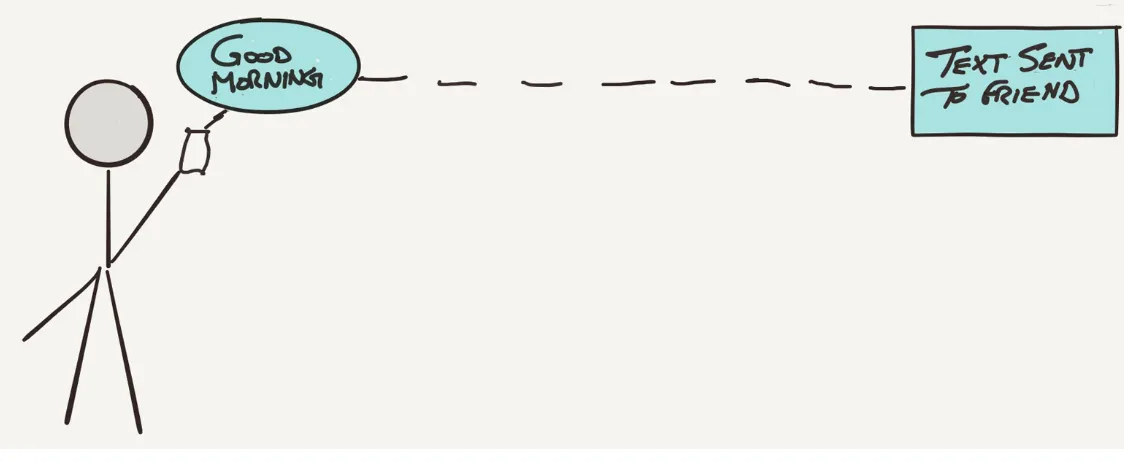
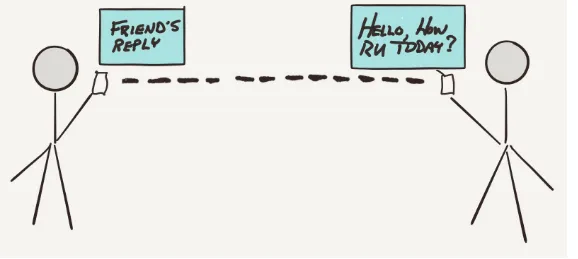
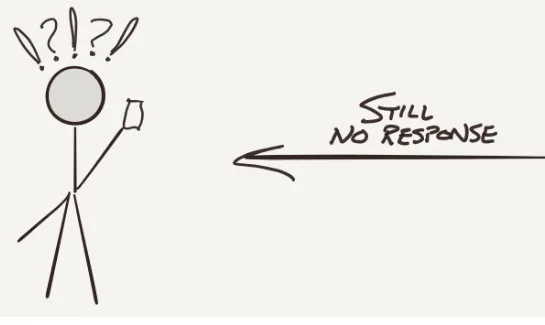
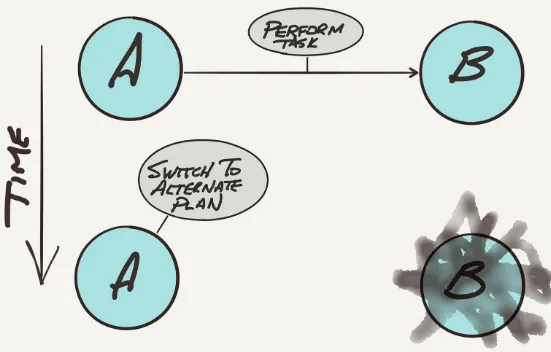
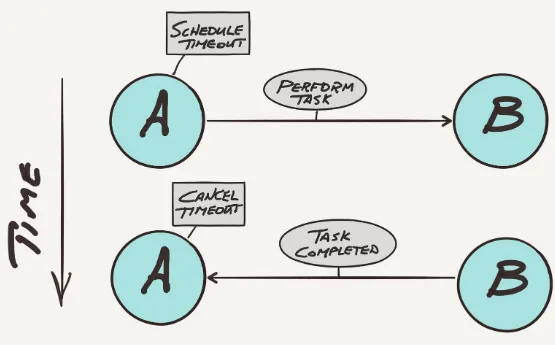
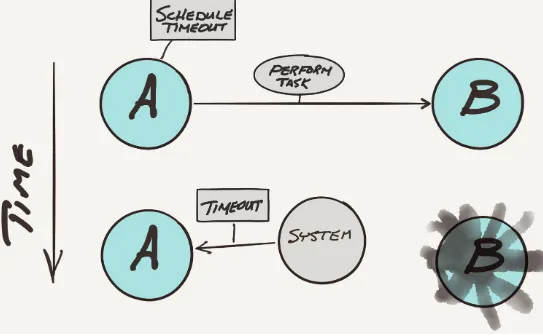
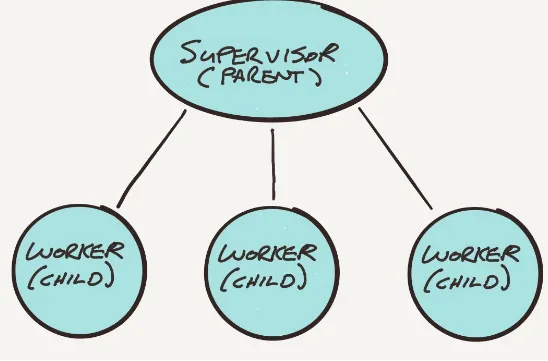
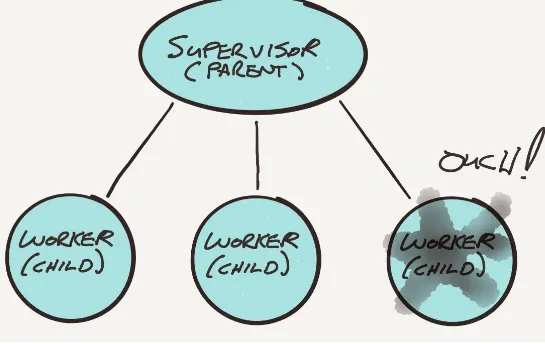
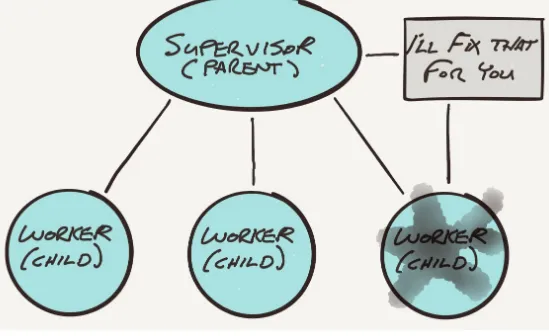
Dokumen terkait
“Barangsiapa yang membacanya dalam sehari sebanyak 100 x, maka itu seperti membebaskan 10 orang budak, dicatat baginya 100 kebaikan, dihapus baginya 100 kesalahan, dirinya
Keterpaduan ketiga kelompok tersebut didasari atas lima faktor pendukung yang saling terkait yakni: (1) keberhasilan pemuliaan tergantung pada ketersediaan dan kekayaan plasma
Salah satu masalah dalam proses produksi kedelai di Indonesia adalah gangguan hama. Serangan hama pada tanaman kedelai dapat menurunkan hasil sampai 80%. Tanaman
Penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat, karunia, dan hidayah-Nya sehingga penulis dapat menyelesaikan penyusunan s kripsi dengan judul
Berdasarkan hasil penelitian yang dilakukan pada bulan Mei sampai Juni 2013 dalam dua siklus PTBK, disimpulkan bahwa layanan bimbingan kelompok dapat meningkatkan
Universitas Pembangunan Nasional (UPN) “Veteran” Jawa Timur, sebagai salah satu Perguruan Tinggi Swasta menghadapi kenyataan bahwa di UPN sendiri khususnya Jurusan Teknik
Sesuai dengan judul pengabdian kepada masyarakat pada tahun 2016 yakni: “ PENINGKATAN KEMAMPUAN GURU-GURU FISIKA SMA SE-KOTA PADANG PANJANG DALAM PEMBUATAN PERANGKAT
Based on the results of the research and referring to the objectives of the study, it was concluded that the MBL-fb was valid by the valid, considered practical by the
