PENELUSURAN CITRA ASET BERBASIS KEMIRIPAN CITRA MENGGUNAKAN FITUR BENTUK, WARNA DAN TEKSTUR SERTA KLUSTERING K-MEANS Jumi¹, Achmad Zaenuddin²
Teks penuh
Gambar
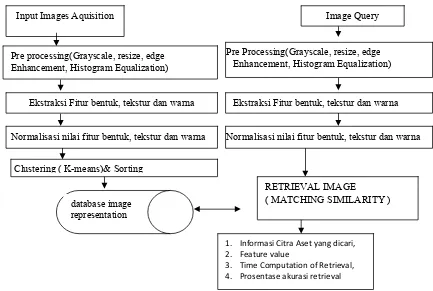
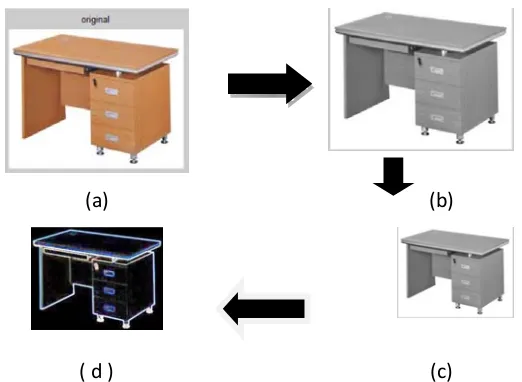
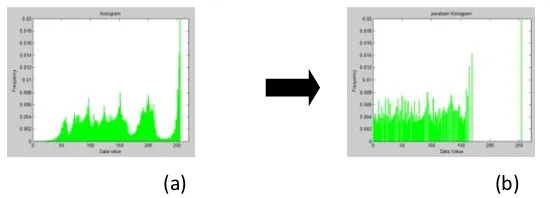

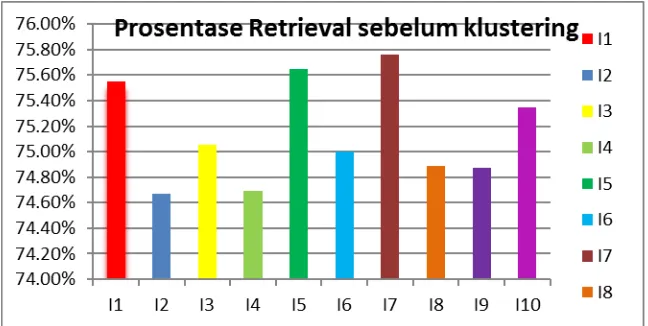
Dokumen terkait
Tujuan dari penelitian ini adalah untuk mengetahui distribusi frekuensi periodontitis pada ibu hamil dengan melihat distribusi frekuensi kejadian periodontitis,
Oleh karena itu, terbukti bahwa hasil pengujian adalah signifikan atau dengan kata lain pelaksanaan Akuntabilitas Sektor Publik berperan signifikan dalam
• Untuk mengetahui hasil biodiesel dengan reaksi transesterifikasi menggunakan katalis K 2 O/H-Za (loading terbaik) dengan variasi perbandingan massa katalis terhadap minyak
(10) Setiap orang atau badan yang menemukan adanya kegiatan pengumpulan sumbangan uang atau barang yang diindikasikan tidak mempunyai izin, atau dilakukan dengan pemaksaan
perencanaan ini dapat dilakukan dengan tes ini dapat dilakukan dengan tes yang yang dilakukan sebelum kegiatan pembelajaran, Hasilnya adalah nanti pengajar akan tahu apakah
Pada tahap pengawasan, masyarakat hanya melakukan 2 dari 3 tindakan manajemen. Bentuk tindakan pemantauan informasi yang dilakukan adalah secara intensif selama 24 jam
Hasil penelitian ini tidak sesuai dengan hipotesis yang dikembangkan oleh penulis yang menyatakan bahwa kinerja lingkungan berpengaruh positif terhadap
Hasil penelitian ini menunjukkan bahwa : (1) Stres Kerja berpengaruh secara negatif dan tidak signifikan terhadap kinerja dengan nilai beta (β) sebesar - 0,386 menunjukkan
