Analyzing the Analyzers Free ebook download
Teks penuh
Gambar
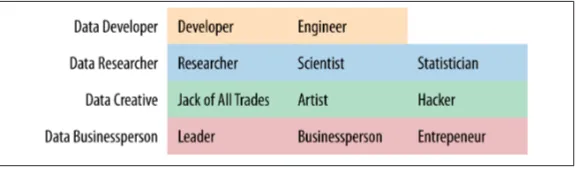
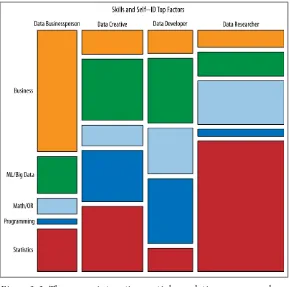

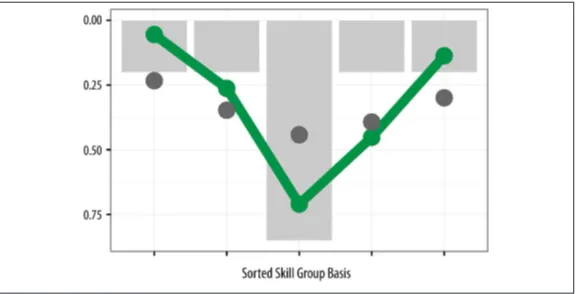
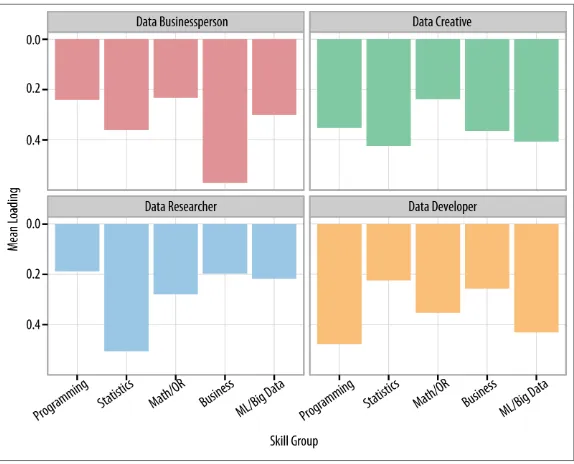
Garis besar
Dokumen terkait
In line to Gopinath and Krisnamurti (2001), my research want to know what blinks stock market prices especially in Jakarta Stock Exchange, the number of transaction
Adapun bukti pembayaran sebagai sayarat pengambilan formulir peserta KKN 2012.. Putri : Mengenakan Jaket Almamater dengan
Diharapkan membawa berkas-berkas Dokumen Penawaran Teknis dan Biaya, apabila peserta lelang tidak menghadiri undangan ini maka dapat digugurkan,. Demikian kami sampaikan atas
This study aims to determine the competitiveness of cocoa commodity in the district of Sigi and the impact of government policies by analyzing the effects of cocoa pric
Pada hari ini Senin Tanggal Sebelas Bulan Juli Tahun Dua Ribu Sebelas, kami yang bertanda tangan dibawah ini Pokja Pengadaan Barang, Pekerjaan Konstruksi dan
menjelaskan cara menentukan nilai determinan suatu matriks.. menjelaskan mengenai matriks singular dan
Dalam rangka Pemilihan Langsung pekerjaan Pembangunan Jalan Usaha Tani Desa Kwala Besar Tahun Anggaran 2013 sesuai Berita Acara Penetapan Pemenang Pelelangan Nomor :
Kontruksi ULP Kota Padang Panjang yang ditunjuk berdasarkan Surat Perintah Tugas Nomor:503/30/SPT/ULP- PP/IV/2013 tanggal 8 Mei 2013, mengumumkan Pemenang Pekerjaan Belanja
