intelligent caching Ebook free download pdf pdf
Teks penuh
Gambar
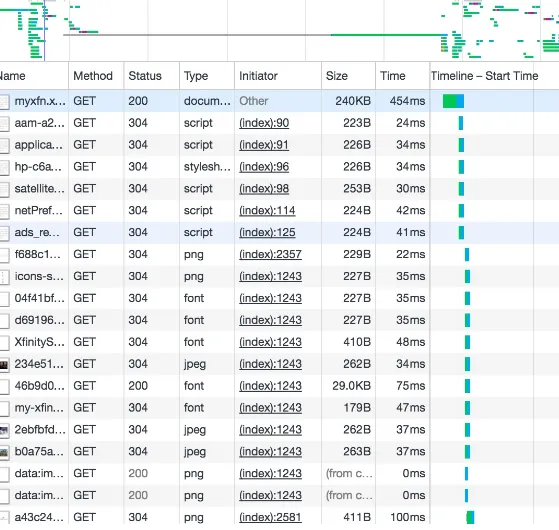
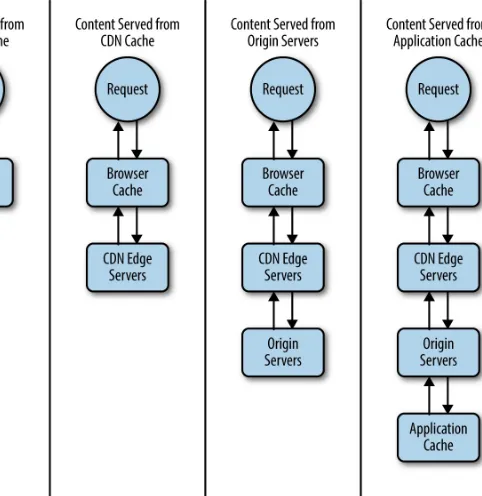


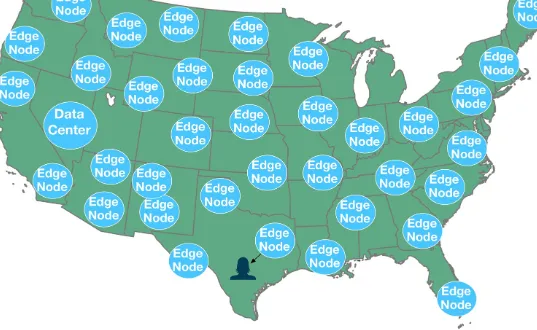
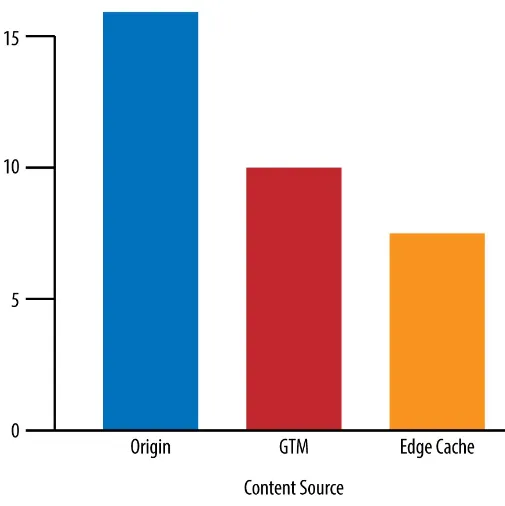
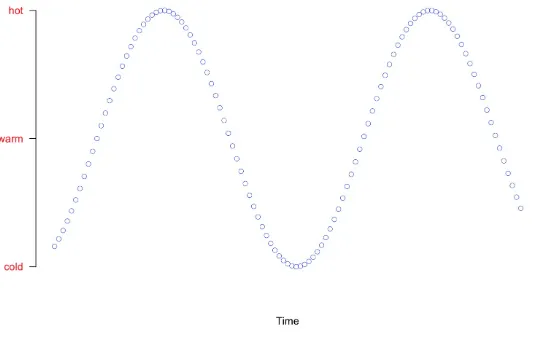
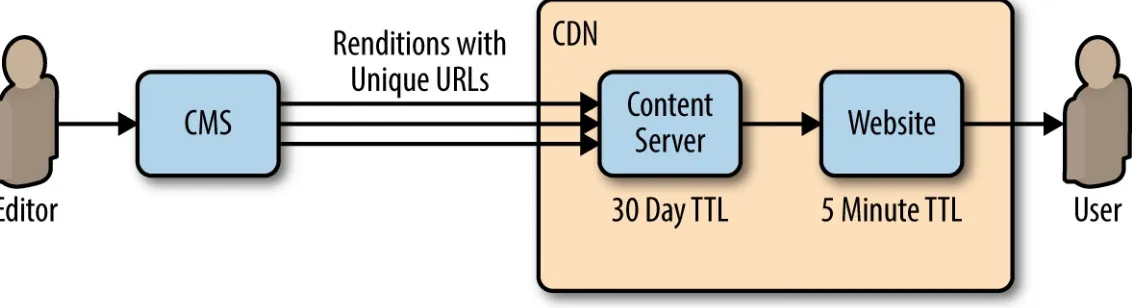
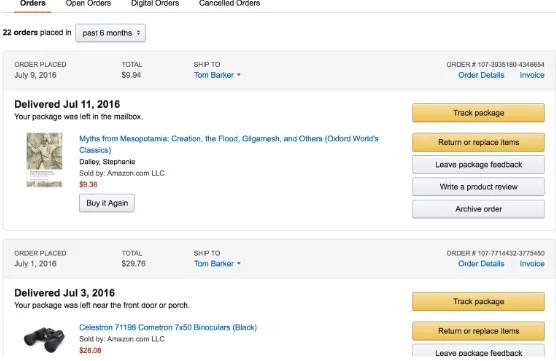
Garis besar
Dokumen terkait
Al-Attas memandang bahwa umat Islam menghadapi tantangan terbesar saat ini, yaitu dengan berkembangaya ilmu pengetahuan yang telah salah dalam memahami ilmu dan
IC Tumor terbatas pada satu atau dua ovarium dengan salah satu faktor yaitu kapsul tumor pecah, pertumbuhan tumor pada permukaan ovarium, ada sel tumor di cairan ascites ataupun
Pers dipaksa untuk memuat setiap berita harus tidak boleh bertentangan dengan pemerintah, di era pemerintahan Soekarno dan Soeharto, kebebasan pers ada, tetapi lebih terbatas
Network Programming menggunakan bahasa C++ untuk beberapa metoda akses jaringan komunikasi data, yaitu dengan cara mengetahui nama sebuah komputer dan alamat
Salah satu masalah dalam proses produksi kedelai di Indonesia adalah gangguan hama. Serangan hama pada tanaman kedelai dapat menurunkan hasil sampai 80%. Tanaman
Suatu penelitian untuk mengevaluasi keunggulan relatif bobot hidup kambing hasil persilangan antara pejantan Boer dengan induk Kacang pada periode prasapih yang dilakukan di
Penelitian ini bertujuan untuk menemukan bukti empiris tentang faktor- faktor yang mempengaruhi ketepatan waktu penyampaian laporan keuangan perusahaan makanan dan
Ada dua hal yang dapat menerangkan keadaan terse but yaitu ( 1) terdapat resiko tinggi dalam hubungannya dengan perlakuan pengeringan dan kerusakan gabah, pada musim
