Learning Apache Spark 2 Ebook free download pdf pdf
Teks penuh
Gambar
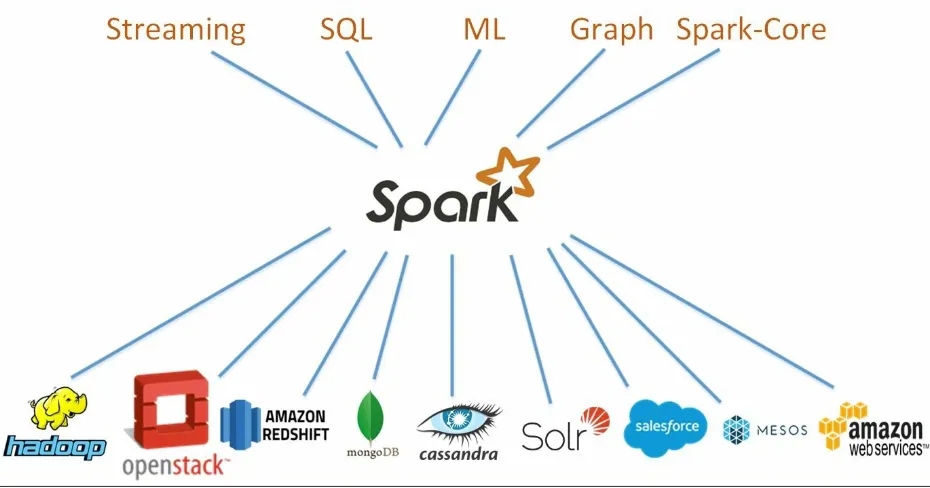


Dokumen terkait
It is false that each pair of positive integers is such that either the first equals the second or vice versa, but it is true that each pair of positive integers is such that either
It then turns the tables and shows you how Perl code can take over the configuration process and configure Apache dynamically at startup time.. Chapter 9 , is a reference guide to
These are JUG-led global programs founded by the London Java Community, and are designed to provide ways for ordinary Java developers to contribute to the development of new
After the third array element gets yielded to the block for printing and control returns to the method, the while loop ends, because we’ve... reached the end of
Two clusters of correlating tool use: one consisting of open source tools (R, Python, Hadoop frameworks, and several scalable machine learning tools), the other consisting of
enumerations. As we’ve discussed, an enumeration is an object type in the Java language that is limited to an explicit set of values. The values have an order that is defined by
We want to call this method from a Groovy script, so first we compile the Java class GreetJava so the class file GreetJava.class is located in the
One way to think of this is that, unlike in some languages, in Python variables are always pointers to objects, not labels of changeable memory areas: setting a variable to a new
