Peringkasan teks berita secara Otomatis menggunakan TF.IDF
Teks penuh
Gambar
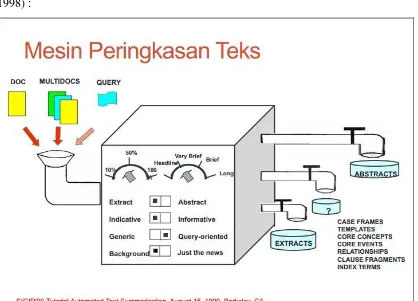
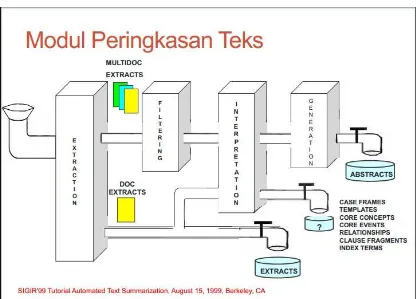
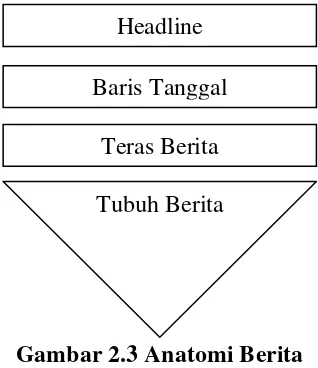
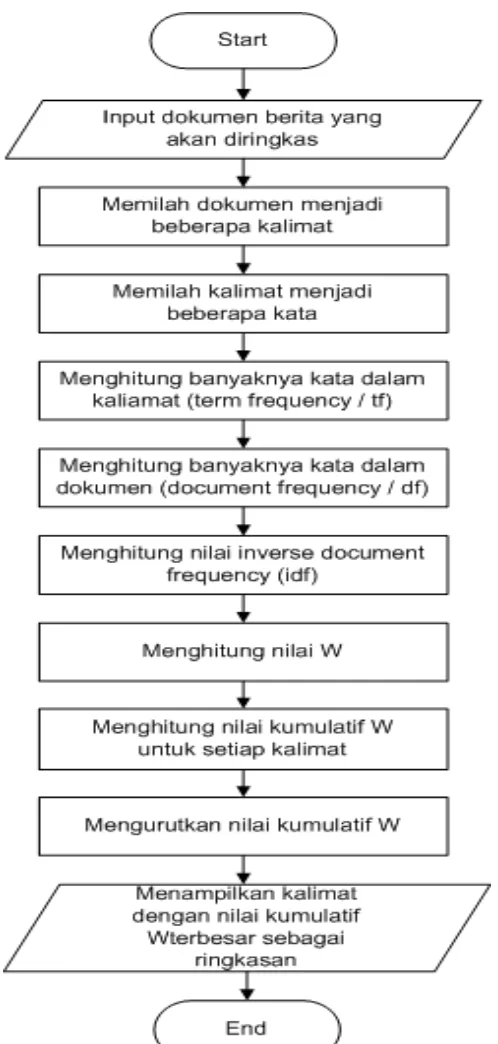


Dokumen terkait
Untuk dapat membentuk kalimat abstrak secara otomatis maka akan diterapkan metode Term Frequency – Inverse Document Frequency (TF- IDF) , karena TF-IDF merupakan
Berdasarkan hasil pengujian dan analisis dari Peringkasan teks otomatis pada artikel berita kesehatan menggunakan k-nearest neighbor berbasis fitur statistik dapat
Salah satu cara untuk mengotomatiskan traceability links penelusuran adalah dengan menerapkan metode pengambilan informasi, seperti istilah term frequency-inverse document
Metode Term Frequency-Inverse Document Frequency (TF-IDF) digunakan untuk memberikan rekomendasi tempat makan berdasarkan kata pencarian (keyword) dari pengguna dan
Metode pembobotan kata yang dipergunakan dalam skripsi ini ialah Term Frequency–Inverse Document Frequency (TF-IDF) & memakai K-Nearest Neighbor (K-NN) untuk
Peringkasan teks khususnya berita dapat digunakan untuk mendapatkan intisari dari teks berita tanpa membaca keseluruhan teks.. Oleh karena itu, dapat dikembangkan
Pada penelitian ini, peringkasan teks otomatis berita yang dibuat merupakan sistem peringkasan dengan inputan beru- pa single dokumen dan secara otomatis
Berdasarkan hasil pengujian dan analisis dari Peringkasan teks otomatis pada artikel berita kesehatan menggunakan k-nearest neighbor berbasis fitur statistik dapat
