Practical Hive Hadoops Warehouse System 3368 pdf pdf
Teks penuh
Gambar
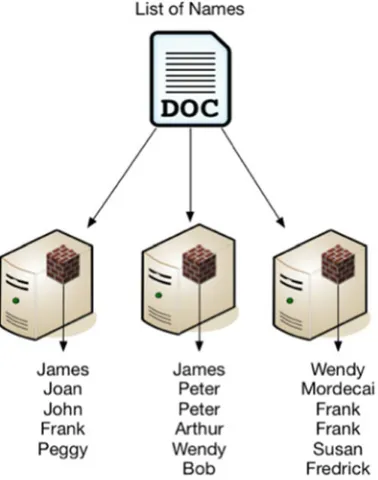
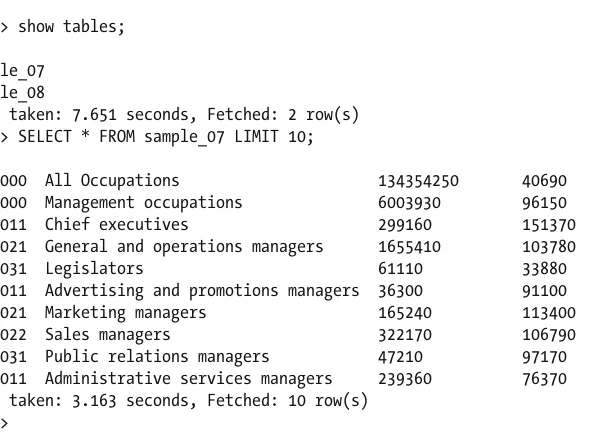
Dokumen terkait
Benar sekali anak-anak yang dikatakan oleh teman kalian, selanjutnya dikelompokkan menjadi berapa materi berdasarkan wujudnya, adakah yang bisa menyebutkannya, coba
POKJA KONSTRUKSI UNIT LAYANAN PENGADAAN KOTA PALU TAHUN ANGGARAN 2011. RUSTAM
[r]
DALAM PEMBELAJARAN MENULIS TEKS EKSPOSISI (Penelitian Eksperimen Kuasi pada Siswa Kelas X SMA Kartika XIX-2 Bandung Tahun Ajaran 2015/2016). disetujui dan disahkan oleh pembimbing:
obesitas berdasarkan rumus Dare di Klinik Bersalin Sumiariani Medan Johor..
tanggal 26 Juni 2006 perihal Usulan Pemekaran Calon Kabupaten Buru Selatan, Keputusan Dewan Perwakilan Rakyat Daerah Provinsi Maluku Nomor 10 Tahun 2006 tanggal 10 Juli 2006
[r]
Suspensi farmasi adalah disperse kasar, dimana partikel padat yang tak larut terdispersi dalam medium cair (Anief,1993).. Evaluasi sediaan suspensi
