What You Need to Know about Machine Learning Leveraging data for future telling and data analysis pdf pdf
Teks penuh
Gambar
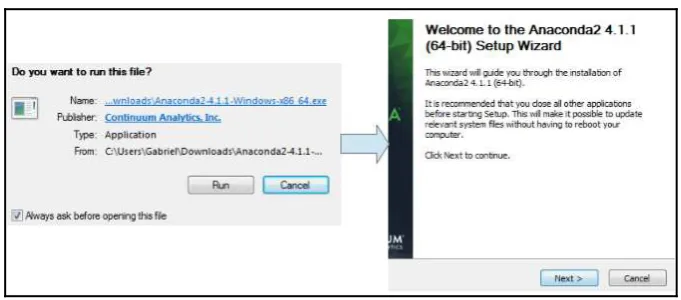
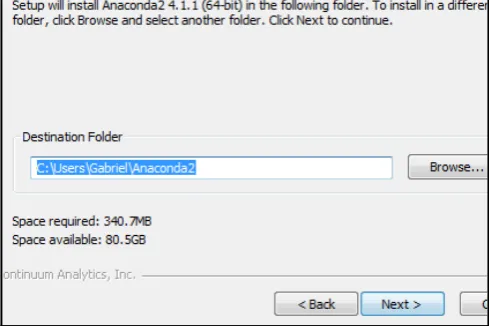
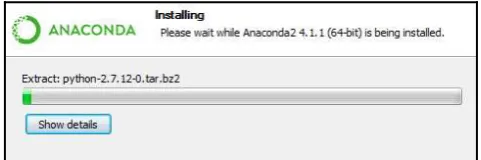
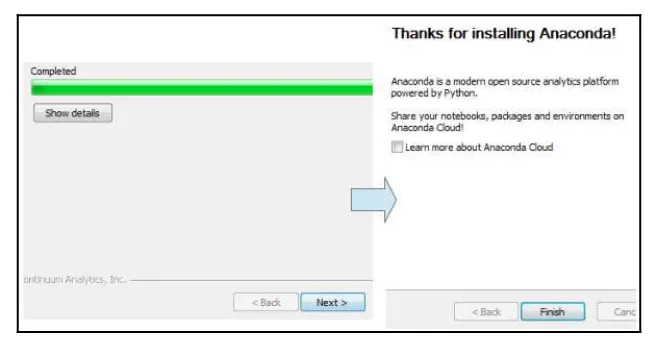
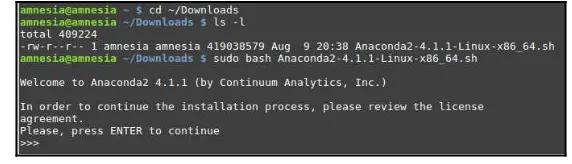
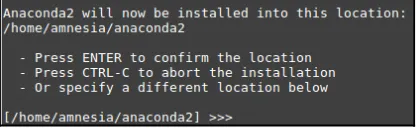
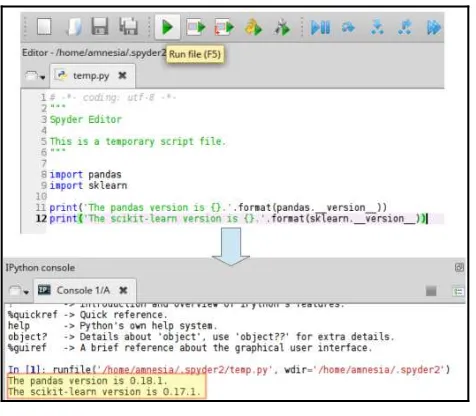
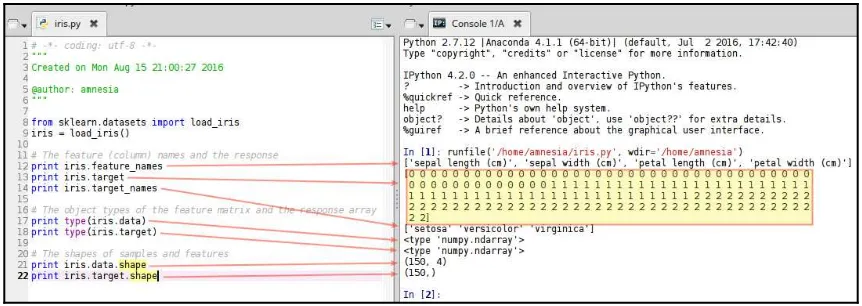
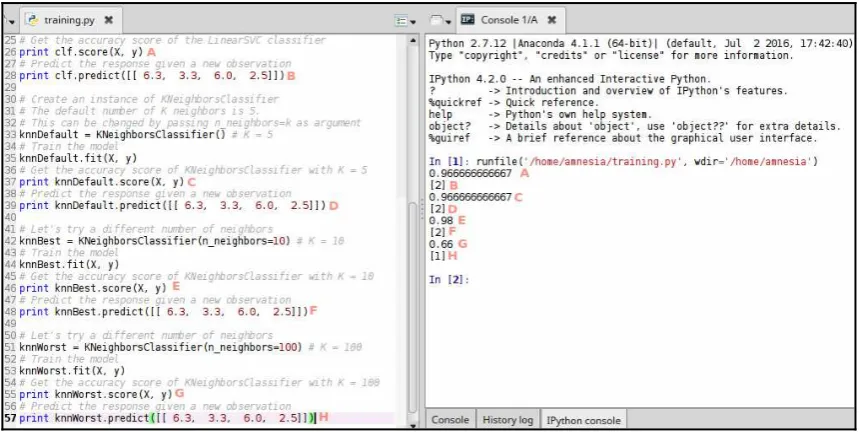
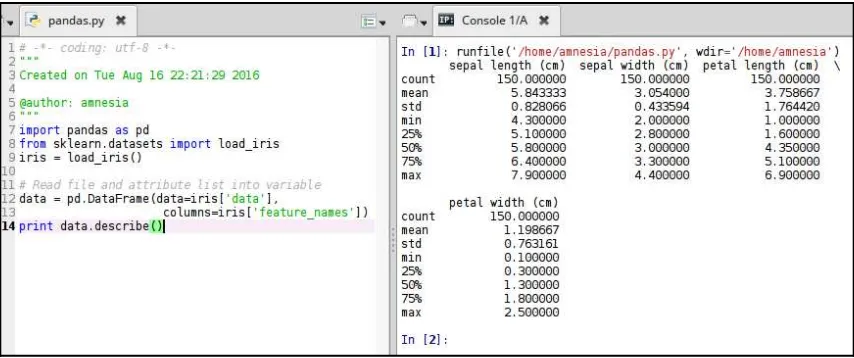
Dokumen terkait
1) Perkawinan harus didasarkan atas persetujuan kedua calon mempelai. 2) Untuk melangsungkan perkawinan seorang yang belum mencapai umur 21 (dua puluh satu) tahun harus mendapat
Kesimpulan penelitian ini adalah mahasiswa akuntansi UPN ”Veteran” Jatim sudah menggunakan Social Networking (Facebook) sebagai media pembelajaran, namun belum maksimal..
Sarana dan Prasarana yang Tersedia di Pasar Induk “Puspa Agro” di Desa Jemundo Kecamatan Taman Kabupaten Sidoarjo.... KESIMPULAN
Parameter yang diamati ada- lah pertambahan jumlah sulur buah, jumlah buah pada sulur, jumlah daun pada sulur buah, rata-rata bobot buah segar, kadar unsur hara pada
Atas dasar pemikiran di atas, maka perlu diadakan penelitian mengenai Faktor-Faktor Yang Mempengaruhi Pengambilan Keputusan Nasabah Dalam Memilih Produk Bank
Desain ini memperhitungkan kekuatan serta daktilitas pada hubungan balok kolom yang akan di aplikasikan pada suatu bangunan yang ada di Surabaya yang mana HBK ( hubungan
Perkembangan teknologi infomasi mengakibatkan terjadinya perubahan yang mendasar pada pekerjaan di berbagai bidang, misalnya di bidang perkantoran. Kondisi seperti
Tujuan penelitian ini adalah untuk membuktikan hipotesis bahwa pembelajaran dengan menggunakan model inside-outside circle akan meningkatkan minat belajar pada mata
