Analisis sentimen data twitter menggunakan K-Means Clustering.
Teks penuh
Gambar








Dokumen terkait
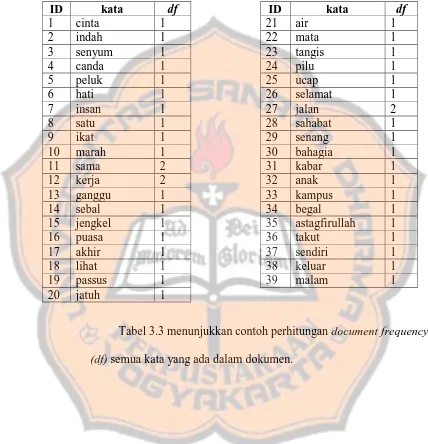
Dalam text mining terdapat beberapa proses yaitu text operation yang terdiri dari tokenizing, stopword, stemming serta pembobotan kata, selanjutnya dapat diolah menggunakan
Nilai dari setiap kriteria tersebut menjadi patokan untuk penyeleksian penduduk yang menjadi prioritas utama untuk mendapatkan bantuan bedah rumah.Dengan mengamati
Tahap ini bertujuan untuk mentransformasikan data menjadi bentuk yang sesuai untuk diproses dalam data mining. Dalam penelitian ini, transformasi dilakukan dari data yang
Kemudian dari tumpukan data teks tweet tersebut dilakukan pembobotan setiapkata (term) yang kemudian hasil pembobotan tersebut diolah dengan algoritma C4.5 untuk
Proses klasterisasi pada PSO relatif lebih lama dibandingkan PSO + K- means, karena PSO memerlukan iterasi yang lebih banyak untuk mendapatkan nilai ADVDC
Berasal dari latar belakang tes gula darah yang harus dilakukan beberapa kali untuk mendapatkan hasil yang akurat dan keterbatassan tenaga medis untuk menentukan deteksi pada
Metode pembobotan kata yang dipergunakan dalam skripsi ini ialah Term Frequency–Inverse Document Frequency (TF-IDF) & memakai K-Nearest Neighbor (K-NN) untuk
Kedua, dari clustering yang terbentuk dari masing-masing kelas, dapat dijabarkan bahwa untuk kelas Teknik Informatika-A, sebanyak 5 10% nilai UTS termasuk dalam cluster nilai
