Data Mashups in R Ebook free download
Teks penuh
Gambar
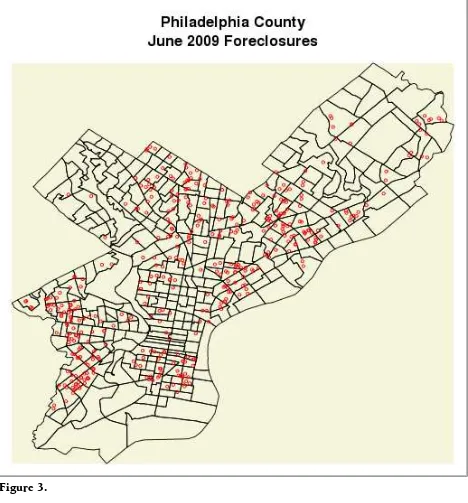
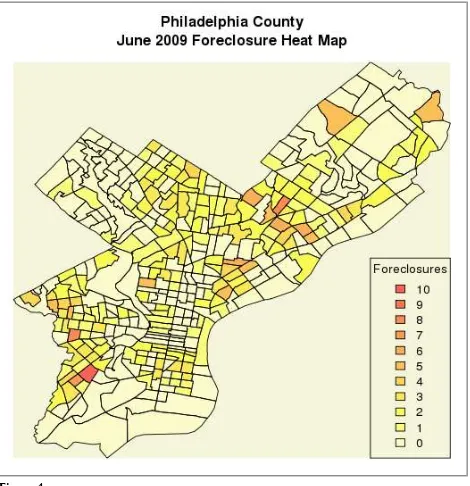
![Figure 5. [9] "Households..Family.households..Householder.25.to.34.years"](https://thumb-ap.123doks.com/thumbv2/123dok/1307277.2010045/21.612.72.541.67.425/figure-households-family-households-householder-years.webp)

Garis besar
Dokumen terkait
Judul Penelitian : Analisa Gangguan Interlingual dan Intralingual dalam Proyek Penerjemahan Bahan Ajar Anak Usia Dini 2.. Nama Lengkap : Mozes
Untuk variabel Produksi dapat disimpulkan bahwa produksi beras nasional tidak berpengaruh positif terhadap impor beras, hal ini dikarenakan pelaksanaan dan proses impor
Tujuan Penelitian ini adalah untuk mengetahui hubungan tingkat pengetahuan tentang kanker serviks dan tindakan Pap Smear berdasarkan teori Health Belief Model pada ibu di
Kebijakan dan upaya yang dilakukan oleh unit pengelola program studi magister dalam menjamin empat aspek berikut: (1) mutu kegiatan pelayanan/pengabdian. kepada masyarakat,
Sebagai Guru Tetap Yayasan pada SDIT AYATUL HUSNA TAHUN PELAJARAN 2015/2016 sesuai dengan tugas pokok yang berlaku.. Kedua : Guru yang bersangkutan wajib melaporkan
Efisiensi dan Persistensi Produksi Susu pada Sapi Friesian Holstein akibat Imbangan Hijauan dan Konsentrat Berbeda, penelitian yang terkait dengan karya ilmiah
1) Indigenous Peoples, local communities and family smallholders, which government and non-government actors, and international organizations must respect and secure in
Formed in 2013, Forest Connect Asia is an alliance of organizations aiming to support forest communities in the Asia-Pacific region in developing their forest based livelihoods
